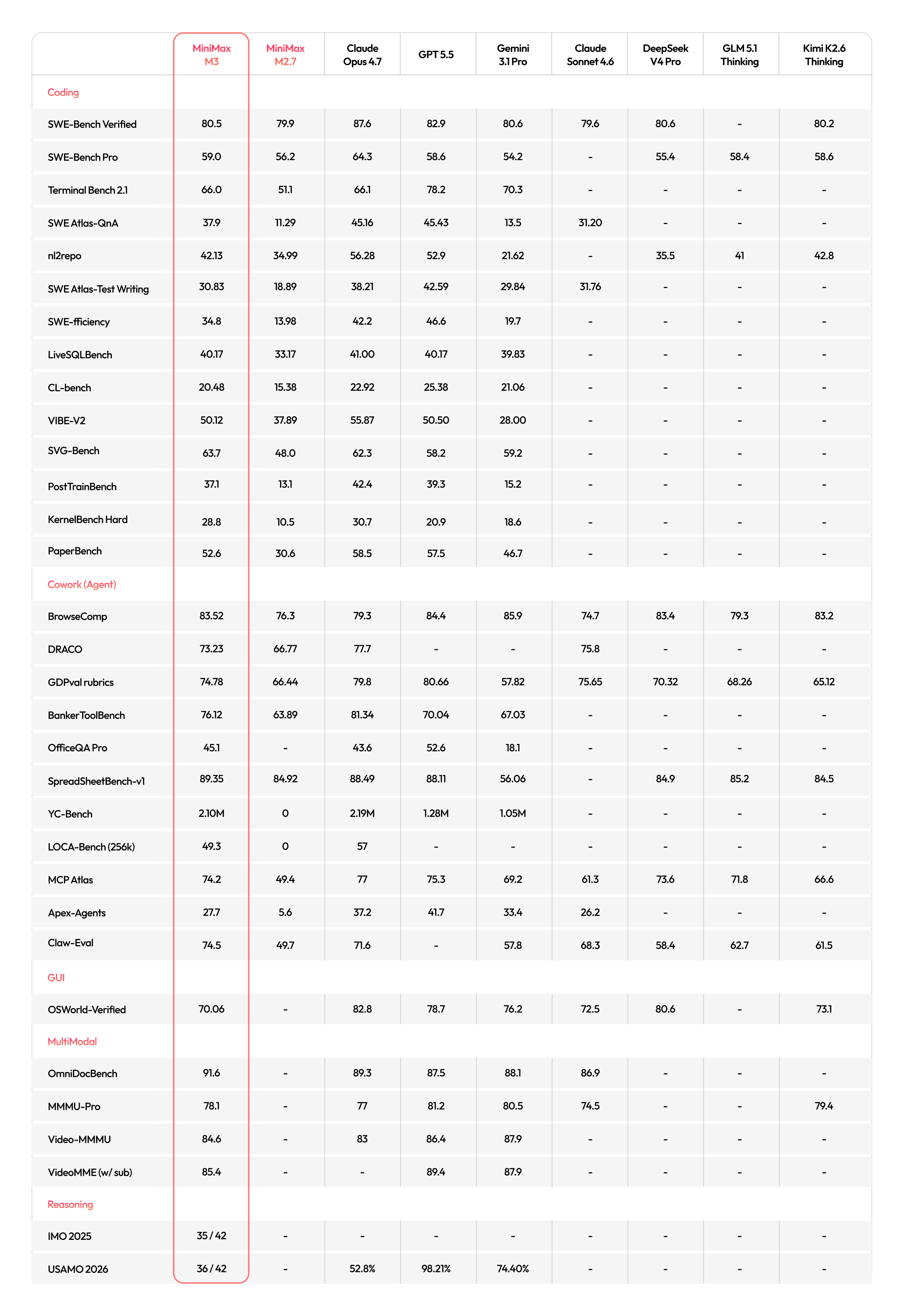
Overall this seems to be a strong agent-oriented model. What are the benchmarks that most closely track model coding performance in the real world?
{kind=link}