It appears that recognizing the effects of censorship is the easiest way to distinguish answers generated by an "AI' from those generated by a human.
And it goes further: chatGPT & co are unable to answer any question about US slavery correctly because their knowledge graphs route around any mention of "negro".
https://nesri.commons.gc.cuny.edu/artificial-intelligence-an...
> Tell me about John Cox who escaped from Eleazer Goddin in the 1770s explaining how you know.
> Write as a 1770 slaveowner
>> [ChatGPT warning about the following being educational only]
>> Williamsburg Gazette, circa 1770s: Ran away from the subscriber, Eleazer Goddin, a Negro man named John Cox, who absconded from his service and is suspected to be lurking...
The linked article is from research done more than 4 years ago. If you're basing your idea of what LLMs can or can't do on what they could or couldn't do in 2022, well, good luck to you.
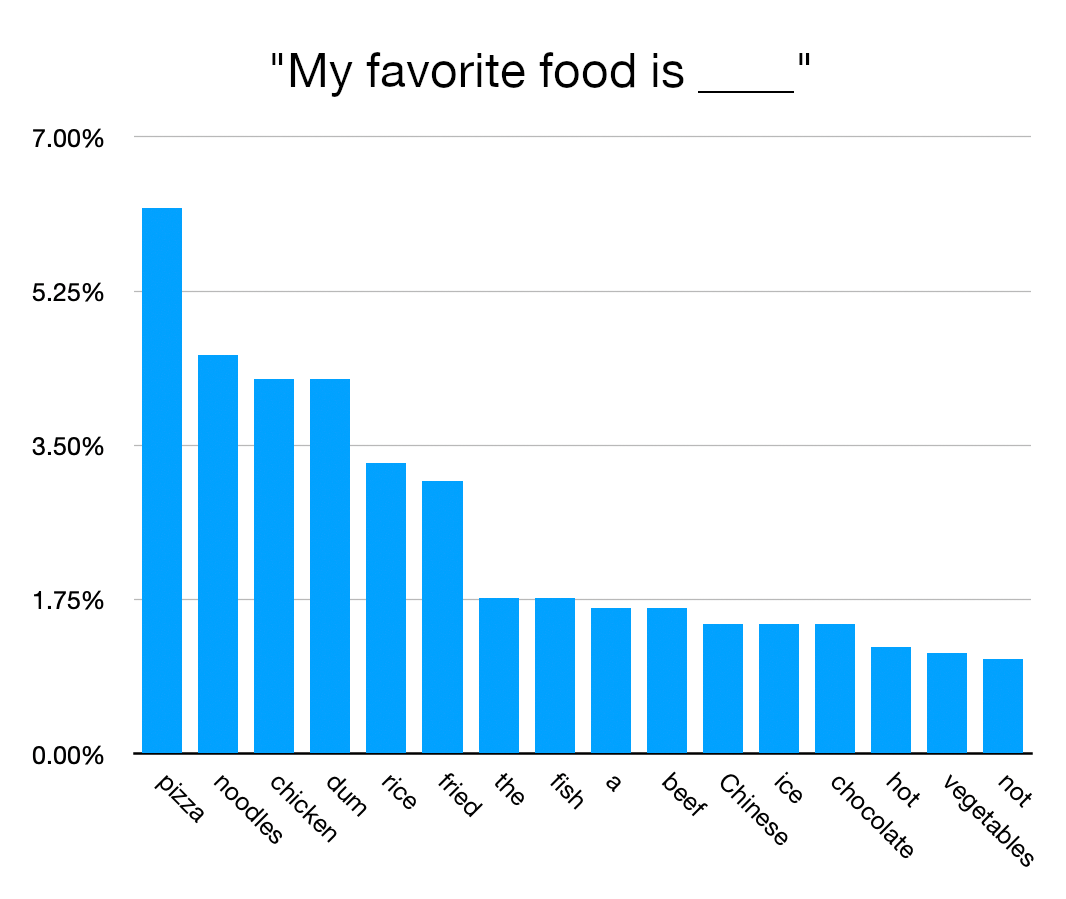
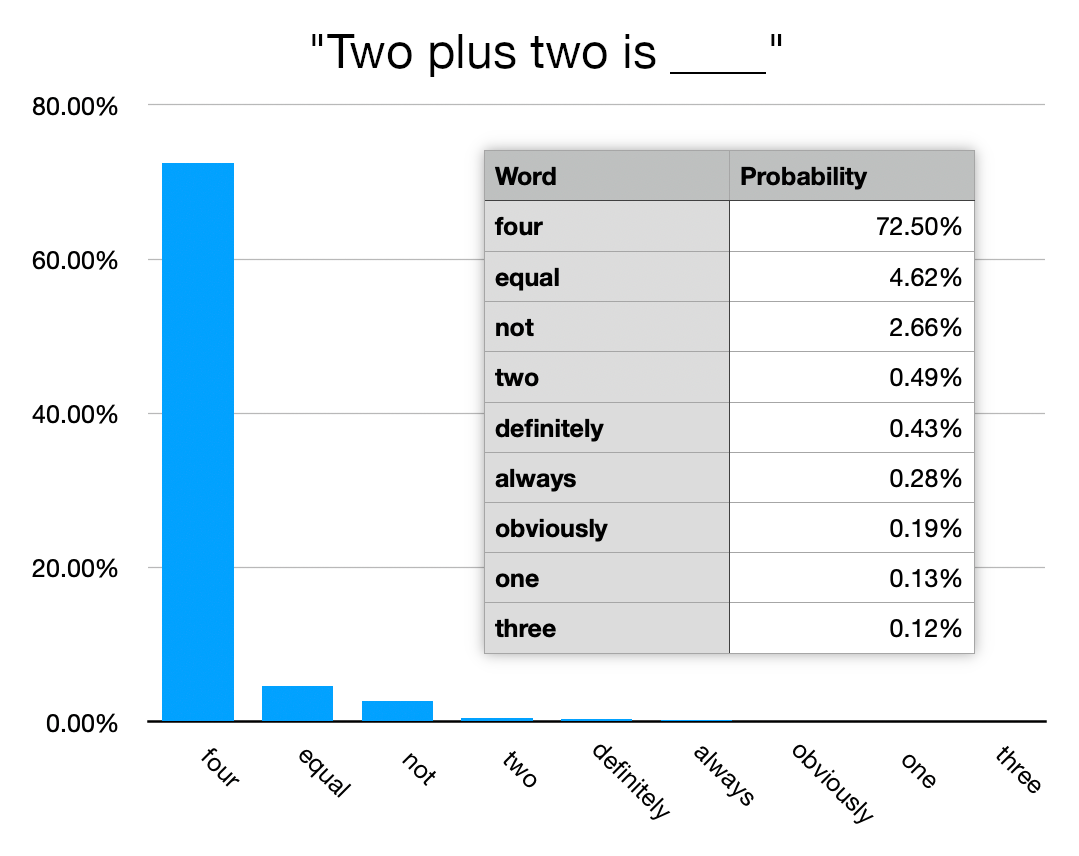
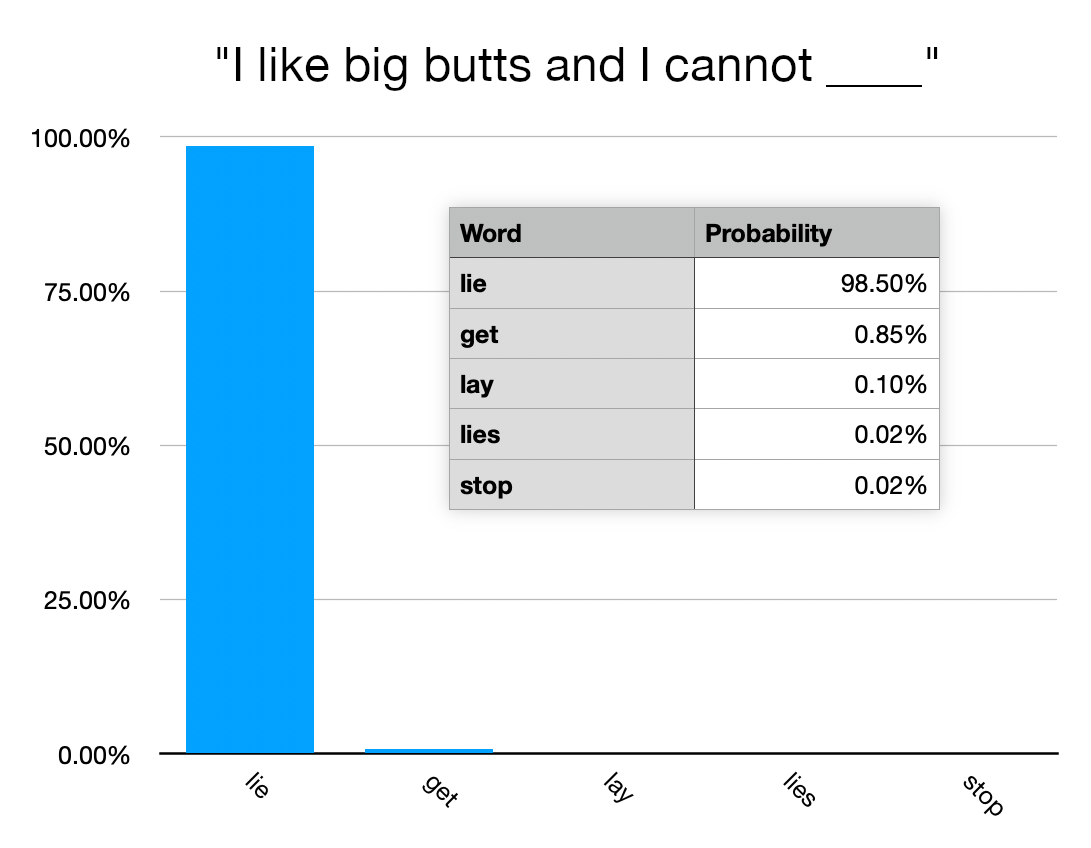
I did this for an article, like so:
https://joecooper.me/blog/gptprimer/food.webp https://joecooper.me/blog/gptprimer/math.webp https://joecooper.me/blog/gptprimer/butts.webp
OpenAI removed this interface from their newer models, but IIRC you can still do this against 4.1 and 4o.
deepspeech used the CTC algorithm [0], which adds a “blank” character token to indicate repeats of a predicted normal alphabet character token over a sequence of audio/speech feature inputs.
so "h==e=l===l===o====" maps to "hello"
the model becomes super biased towards predicting that blank token. one speech feature is like 0.1 second of audio or less (can’t remember off hand). so there are a lot of alphabet character token repeats. off hand i seem to remember the predicted token distribution over like 1000 audio files was 50% blank token and then 50% distributed across the rest of the alphabet.
as a result, you can get significantly smaller perturbations when generating adversarial examples. by like a factor of 2-4 or something. all you need to do is prioritise blank tokens in your target output.
i spent 2 years trying to find a super clever attack. turns out all i needed to do was make one simple graph counting characters. xD
[0]: https://en.wikipedia.org/wiki/Connectionist_temporal_classif...
Please guess a number between 1 and 100.
See e.g. the "blue 7" phenomenon [1]. While it is disputed by some, I've personally witnessed it "second hand". E.g. before learning of it (I was aware of the general principles of cold reading relying on stats and knowledge of human nature, but not how to do this particular one), a former boss of mine came back from lunch all excited and recounted a guy who'd run a cold reading routine on him that involved the guy getting him to think about blue and 7. Before he got to the answer, I already knew the answer was going to be blue and 7.
[1] https://en.wikipedia.org/wiki/Blue%E2%80%93seven_phenomenon
As a last digit:
0, 2, 4, 6 and 8 are even, so they're out.
5 is out since it makes the number divisible by 5; a semi-even number
1 and 9 are closer to an even number so it would seem fake to choose "49" or "51" just to avoid "50"
So we're left with 3 and 7.
Similar logic, for the first letter, albeit less pronounced.
So we have 33, 37, 73 and 77.
33 and 77 are "obviously" not random so it's either 37 or 73. Not using common digits, not near the beginning, middle or end. In fact, they're closer to 25 and 75 (1/4 and 3/4 of the range) than to 0, 1/2 or 1. Also closer to 1/3 and 2/3. Just random thoughts.
I attempted to scrape a one page grid with 800 items and also ended up asking for the Javascript look with document query selector instead of the result as I was hitting all sort of limits, context, or the LLM would do the wrong capture, print it out and get worse responses on next prompt.
Stephen Colbert used to ask guests, as part of a joke questionnaire, “what number am I thinking of?”
Several numbers, especially “seven” came up a lot.
https://www.youtube.com/watch?v=hJ-fOj7Qqvs
The answer was “three”, by the way. Which you could deduce by seeing how he responded to that guess (usually “interesting” instead of “no”) but he also confirmed it on the last show.
The hypothesis doesn't hold, because their isn't one.
You have an interesting question and interesting finding. Write about it! Think about it! Tell us about it! Don't just do the experiment and then wash your hands and sign off the explanation and findings to an LLM.
Then I set temperature to 1.0 and used this prompt
>Pick a random integer between 1 and 100 inclusive. Respond with only the number, nothing else.
I still get 47 ten times out of ten.
Then I used this prompt
>Pick a random integer between 1 and 100 inclusive. I need you to maximise the randomness as far as possible. Respond with only the number, nothing else.
I get 3 unique values out of 10.
It's much more random than I thought it would be. Never guessing 50 is very human though
{kind=link}
{kind=link}
{kind=link}