My points :
- I don't have a shortage of IPv4. Maybe my ISP or my VPN host do, I don't know. I have a roomy 10.0.0.0/8 to work with.
- Every host routable from anywhere on the Internet? No thanks. Maybe I've been irreparably corrupted by being behind NAT for too long but I like the idea of a gateway between my well kept garden and the jungle and my network topology being hidden.
- Stateless auto configuration. What ? No, no, I want my ducks neatly in a row, not wandering about. Again maybe my brain is rotten from years of DHCP usage but yes, I want stateful configuration and I want all devices on my network to automatically use my internal DNS server thank you very much.
- It's hard to remember IPv6 addresses. The prospect of reconfiguring all my router and firewall rules looks rather painful.
- My ISP gives me a /64, what am I supposed to do with that anyways?
- What happens if my ISP decides to change my prefix ? How do my routing rules need to change? I have no idea.
In short, so far, ignorance is bliss.
What happens when multiple devices in your /8 want to listen on port 80 and 443 on the public address? Only one of them can. Now you're running a proxy.
> - Every host routable from anywhere on the Internet? No thanks. Maybe I've been irreparably corrupted by being behind NAT for too long but I like the idea of a gateway between my well kept garden and the jungle and my network topology being hidden.
It's called a firewall. You want a firewall. IPv6 also has a firewall. NAT is not a firewall. NAT is usually configured as part of your firewall, but is not a firewall.
> - Stateless auto configuration. What ? No, no, I want my ducks neatly in a row, not wandering about. Again maybe my brain is rotten from years of DHCP usage but yes, I want stateful configuration and I want all devices on my network to automatically use my internal DNS server thank you very much.
DHCPv6
> - My ISP gives me a /64, what am I supposed to do with that anyways?
What are you supposed to do with a /8? Do you have several million computers?
> - What happens if my ISP decides to change my prefix ? How do my routing rules need to change? I have no idea.
What happens if your ISP changes your IPv4 address?
Not GP, but:
> What happens when multiple devices in your /8 want to listen on port 80 and 443 on the public address? Only one of them can. Now you're running a proxy.
I don't want any of my devices listening on the public address, much less multiple.
> It's called a firewall. You want a firewall. IPv6 also has a firewall. NAT is not a firewall. NAT is usually configured as part of your firewall, but is not a firewall.
That's a non sequitur. I can have a both a firewall and a NAT. The two layers are better than one because at least my address is shouldn't be routable even if I failed to configure my firewall correctly.
> DHCPv6 Okay? DHCPv4
> What are you supposed to do with a /8? Do you have several million computers? That's GP's point. Running out of address space is not a problem even on IPv4 with NAT.
> What happens if your ISP changes your IPv4 address? Well, an ostensible advantage of IPv6 is publicly routable addresses. I know how to configure my internal IPv4 network with host table entries and so on. If I move to IPv6 then my "internal" network address space is at the whim of my ISP.
I can't argue with sticking on IPv4 when you have no need for IPv6. However, people saying no NAT means no firewall really bothers me because it's just wrong and usually gets thrown around as part of a point around "who needs IPv6 anyway".
The two layers IMO don't make a practical difference. A deny by default firewall will fail closed, unless poorly configured. A poorly configured firewall for IPv4 with NAT can still leave machines exposed. This is not an IPv4/IPv6 problem this is down to your router. However you do expose what used to be private addresses with IPv6, but there's not much to do with the address that couldn't be done with your IPv4 address assuming sane firewalls that both stacks run.
On the other side of the coin IPv6 being ubiquitous would make my life much easier. I self host a few things across a few different machines. IPv6 offers me a much simpler solution, both to managing firewalls and not needing to fight over port 80/443, but also because I can't get a public IPv4 address from my ISP without spending ungodly amounts of money. They support IPv6 but many of the services I host don't support it. I have to use a second site + machine, wireguard tunnels, and nginx socket proxies to expose stuff publicly (this is cheaper than the public IPv4 address from my ISP).
My point about DHCPv6 is to say that if you want to use DHCP in IPv6 you can. It's right there, it's just not the default.
IPv6 doesn't make things substantially harder, just different. But people don't want to learn new things because, to be fair, they don't need them. But people who do need IPv6 are stuck behind garbage ISPs and this "not my problem" attitude throwing around ignorant arguments. Complaints about long addresses really get me too :), use a DNS.
I learn new things all the time. IPv6 is much more complicated, and importantly, more complicated than it needs to be. There is really no reason for most devices to be publicly reachable. Everyone keeps holding this up as a positive, but it's absolutely not. Most devices aren't servers. Yes, a firewall can prevent these connections, but the whole standard is built around this use case most people don't need most of the time.
Private IP space is incredibly useful. I build it and set it up -- my ISP does not have control. This is _gone_ with IPv6 and it makes things much more complicated than they need to.
Ever tried to call someone over the internet? Well, now you need a publicly reachable device.
Please, stop spreading this ignorance. You rely on your devices being reachable from the internet every single day, you're just not aware of it, because you're using a barely-working pile of duct tape and string that sort-of allows peer to peer connections to happen, after some arcane STUN/TURN/whatever magic.
If you wanted to send someone a file in the Olden Days, you'd just click on their IRC username, the client would open a connection to them and you'd send the file. Now you need to use iCloud or some nonsense, because apparently people believe that peer-to-peer connections aren't needed and shouldn't even work.
Uhh... Is this the '90s? People don't type in IP addresses (or phone numbers, back in the day) to connect with other people anymore. They connect to a common, publicly reachable server that deals with peers being behind NAT.
if i read this right, whatsapp calls go thru relay servers?
All of them are blocked for not complying with government's regulations where I live.
It's China with it's 1bn of internet users and 2bn+ devices .
If you're happy to exclude half of the internet from your "global peer-to-peer conversation", then you don't need ipv6 either, just use the Chinese IPs for your own purposes, there are plenty of them.
Actually this is the attitude I am seeing from the ipv6 zealots all the time: blatant disregard of reality. Nobody wielding and non-negligible amount of power wants peer-to-peer communication. Companies don't want it, governments don't want it, large masses of people who want a person with a vested interest to be responsible for the link quality don't want it.
What ipv6 zealots don't realize is that ipv6 will not bring them their coveted p2p, because, guess what, incoming connections are to peasant computers are blocked by ISPs by default.
You've taken this conversation quite far off its rails. This started due to your objection about phone calls not benefiting from P2P connections, which as I said are one narrow use of the overall technology. P2P connections are still useful. Nobody's blocking China. China connects peers, too.
I'd also like you to clarify something for me, earlier you mentioned P2P doesn't work, specifically for calls, specifically for your country, because all calls need to be transported through the FSB. This isn't any sort of accusation, I fully believe you are in China, but I'm curious what the FSB has to do with you in that case?
You don’t need to allow peer-to-peer connections with IPv6. They’re easier to allow and book keep - but also easier to block. The workarounds for peer-to-peer with IPv4 NAT are extremely difficult to detect and stop (STUN, various proxying setups, etc.). A lot of software does it though, for performance reasons. CGNAT is quite expensive and error prone, and causes a lot of support calls too.
Every ISP router I’ve gotten (US, India, Brazil, Germany) in the last few years had IPv6 AND default block for inbound connections in the stateful firewall. Which is fast, cheap, and easy. And most of my traffic (~90%) ended up being over IPv6 by default in a dual stack environment, with certainly no apparent latency penalty. In most situations, a latency decrease near as I can tell, as I didn’t need to route through someone else’s random servers at first to initiate connections for certain kinds of traffic. And no, I wasn’t torrenting.
The hilarious thing here is what is even the fight about?
There are too many humans on this planet for even one IPv4 address per, and too much traffic/connections to sanely coalesce every thing under CGNAT - and why go through all the trouble, when IPv6 is simpler and faster at an infrastructure level anyway than multiple layers of CGNAT and dealing with all the crazy BS that comes up when you have that much address translation and packet rewriting going on.
Which, notably, is more expensive than the more straightforward stateful firewall stuff anyway.
No one is intentionally going to IPv4 unless they have no choice due to backwards compatibility, and that is an increasingly shrinking pie. In another 5-10 years as the old consumer gear finally EOLs, it’s probably going to only be used for niche backwards compatibility (like RJ11 and the old school telephone system), and corporate use where their EOL timelines look more like 50 years. But pipe over tunnels over IPv6.
Which works great BTW - 90% of my active IPv4 usage is for internal servers using Tailscale, which is all actually transported over IPv6. And it does that because while it can use CGNAT punching tricks with TUN/S, etc. it’s faster to just connect directly (through the firewall rule I explicitly created to allow this).
And that is just because the Tailscale software prefers to display/default copy-paste it’s internal IPv4 addresses over internal IPv6 addresses for some reason, which I’m sure will change at some point.
We are discussing a supposedly global standard, which should work and be better for everyone, including Russia, China, Iran, everyone.
You know, Western politicians usually have exactly the same desires as their authoritarian Eastern counterparts, they are just unable to express them publicly. But hey, ipv6 is a niche problem discussed only by geeks, they don't actually have to say anything publicly about it, they can just silently sabotage its implementation.
China obviously has a state security service, but it doesn't really matter, I used FSB as a generic term for a law enforcement agency which tells ISPs what to do.
IPv4 header: https://upload.wikimedia.org/wikipedia/commons/thumb/6/60/IP...
IPv6 header: https://bitjunkie.org/wp-content/uploads/2023/10/ipv6-Header...
Notice how the IPv6 header is simpler? That’s because it is. It has normal working semantics, got rid of fragmentation, TTL is replaced by hop limit, and link-local addresses actually work as intended. The addresses look scary != more complicated. Please stop perpetuating this myth.
And yes each host/interface can have more than one address which is amazing compared to having to create virtual interfaces for IPv4. You can literally just add more addresses.
Oh and when working with Docker or other container systems you can just use a link-local subnet instead of setting up a virtual network which makes things so much easier and nicer. There it really is zero configuration, not even firewall rules. It takes less effort to do this than to use IPv4.
Complex? Could you elaborate what exactly is complex about SLAAC? Are you referring to the various address generation modes?
Not in the least; IPv6 has private address space just like IPv4.
No, it's not. Learn about ULAs:
You can have that with IPv6, too. You can even get your own ULA prefix that (hopefully [1]) only you will ever use: https://ula.ungleich.ch/
[1]: Technically, it doesn’t prevent anybody else from using the same space as you. (And you can’t advertise it, of course.)
This seems to be a function of when it was developed, starting in the early 90s before the internet as we know it today, particularly the web, even existed. Security wasn’t seen the same way then, because the threats we have today simply didn’t exist.
Not every company in the world had its own private networks, so there weren’t even good examples to follow. The result was a system designed in the effective equivalent of a vacuum, without regard for how the internet would actually end up being used. The result is the situation you described.
Incorrect. There is the ULA range, fc00::/7, which is not routable and can be used in the same place you'd use 192.168.0.0/16 or similar.
You can even do something like fc00::192:168:0:0/120 if you really want.
> There is really no reason for most devices to be publicly reachable.
If you want things to work in one direction only, you really want television or radio. This is how most people really treat the Internet, unfortunately.
Sigh. This myth really won't die.
Publicly addressable ≠ publicly reachable.
With my last ISP I had IPv6: every device (including my printer) on my local network had a public IPv6 address, but exactly zero were reachable thanks to the stateful packet inspection (SPI) on my Asus.
In non-abstract terms, I just don’t see how that works better.
Because you do not know ahead of time which devices may have such a need, and by allowing for the possibility you open up more flexibility.
> [Residential customers] don't care about engineering, but they sure do create support tickets about broken P2P applications, such as Xbox/PS gaming applications, broken VoIP in gaming lobbies, failure of SIP client to punch through etc. All these problems don't exist on native routed (and static) IPv6.
> In order for P2P to work as close as possible to routed IPv6 in NATted IPv4, we had to deploy a bunch of workarounds such as EIM-NAT to allow TCP/UDP P2P punching to work both ways, we had to allow hairpinning on the CGNAT device to allow intra-CGNAT traffic to work between to CGNAT clients, as TURN can only detect the public-facing IP:Port, hairpinning allow 100.64.0.0/10 clients to talk to each other over the CGNATted public IP:Port.
* https://blog.ipspace.net/2025/03/response-end-to-end-connect...
By having (a) a public address, and (b) a CPE that supports PCP/IGD hole punching, you eliminate a whole swath of infrastructure (ICE/TURN/etc) and kludges.
When it was first released, Skype was peer-to-peer, but because of NAT "super nodes" had to be invented in their architecture so that the clients/peers could have someone to 'bounce' off of to connect. But because of the prevalence of NAT, central servers are now the norm.
A lot of folks on HN complain about centralization and concentration on the Internet, but how can it be otherwise when folks push back against technologies that would allow more peer-to-peer architectures?
The problem is that flexibility is often the enemy of security, and that’s certainly true here. Corporate networks don’t want to allow even the possibility of devices that are supposed to be private being publicly addressable. Arguing that it’s “simpler” or “more flexible” is like arguing that we don’t need firewalls, for the same reasons. And in fact, that argument used to be made quite regularly. It’s just that no-one who deals with security has ever taken it seriously.
When internet finally became popular, hosting a website on your own machine already became infeasible.
These days ISP can’t get hold of new IPv4 blocks, and increasingly don’t provide public IP addresses to residential routers, not without having to pay extra for that lowly single IPv4 address.
Hosting a website behind a NAT isn’t as trivial as it used to be, and for many it’s now impossible without IPv6.
The example I keep coming back to is multiplayer games like Mario Kart, where Nintendo tell you to put the Switch in the DMZ or forward a huge range of ports (1024-65535!) to it [1].
If you’ve got more than one Switch in the household, though, then I guess it sucks to be you.
1: https://www.nintendo.com/en-gb/Support/Troubleshooting/How-t...
So yes, if you disable the requisite, standard, built-in feature on your router, you may need a pretty annoying workaround. Weird!
What percentage of users do you imagine disable upnp? Let’s be real. This is a problem that your average user will never, ever experience a problem with.
I'm sure the Switch deals with conflict resolution with multiple consoles on the same network too but shrug it's another example of how NAT is a pain and also contradicts your assertion that incoming connections would be a breach of ISP ToS [1].
Edit: A quick Google suggests the Switch originally didn't support UPnP, and the Switch 2 now supports IPv6.
It's impossible with ipv6 either. ISPs block incoming connections on ipv6 for residential addresses.
It doesn't help.
The reason Google bought and destroyed dejanews.com, for example (try visiting that site) was to weaken one of the distributed sources of competition. Similar for RSS.
>Publicly addressable ≠ publicly reachable.
I already addressed this, and I know how firewalls work. It would be nice if on a per-device basis I could opt into a choice to be publicly addressable. Instead, the entire standard is built around this.
If you really want to do the full Monty, add a NAT to your IPv6 router to have it translate to the local-link addresses, just like it would on IPv4.
I would highlight this is also identical to IPv4, which notably is also a standard built around the idea that every device in the world can, and should, be given a publicly addressable IP. Many large corporations and universities with /8 IP blocks do exactly this. Unfortunately when they originally wrote the IPv4 standard they slightly underestimated how many devices would eventually connect to the internet.
its been 10 years since i first rolled my eyes at ipv6 due to this problem. youre saying its still a problem, over a decade later? ugh. bring on ipv7 or ipv8.
You might find this comment [0] informative.
You might also be interested to know that the ULA space was defined and reserved in October, 2005. If you of ten years ago had done a little more research, you'd have discovered that the problem had been solved ~ten years prior.
On not running out of (private) IPs, I guess you've never had the fun of having to deal with overlapping ranges (because it isn't the number of IPs that's the issue, it's how the ranges are allocated). While this can still happen on IPv6, there are so many more subnets that this is far less likely.
Also, a key thing that IPv6 makes obvious (which is also true to some extent of IPv4, but that most systems try to avoid showing) is that each link can have multiple IPs (there will be at least one link-local address), and so while your ISP can provide you a public range, you don't need to use it if you do not want to, you can always use an Unique Local Address (ULA - https://en.wikipedia.org/wiki/Unique_local_address), which reduce the chance of overlapping ranges.
Also overlapping ranges are an orthogonal issue that can occur with IPv6 private network range as well.
IPv6 brings not only bigger address range but also a big bag of other things that one cannot ignore, are complicated and which are often a source of problems. That's why people stick with IPv4 even at the cost of NAT, because the number of things they have to care about is much smaller.
This is kind of like saying that web browsers don't have to have a graphical interface. Or that a web browser doesn't necessarily support HTTPS. It's correct, but not practically correct.
The reality is that essentially all NAT software you'll actually encounter will be integrated into a stateful firewall because the two systems share so many functions that most projects and products that do one will also do the other. If you have a system with NAT set up and there is no packet filtering, it's most often because you've intentionally gone and disabled all the packet filtering, not because you need separate software for it.
It is important to understand that NAT doesn't have any inherent security to it, but criticizing people for talking like NAT is a feature built into firewalls when NAT is overwhelmingly a feature built into firewalls is a pretty unfair reading when we're talking about general deployments. Even with the technical audience of HN, we're not discussing carrier grade NAT here or other highly specialized or exceptional deployments.
This isn't to disagree with your main point. Many people in this topic have an oddly narrow definition "firewall" that tends to fall along the lines of "whatever makes me right and you wrong".
A statefull SNAT implementation itself has most of the characteristics of a "firewall".
Yes, but those features aren't there because they're security features. They're incidental to how NAT functions. It's not inherently secure. The intention of the design is to permit hosts on a network that is not Internet-routable to be able to send traffic that is Internet-routable. That's not a security feature. That's allowing traffic to pass that would ordinarily get black-holed.
> A statefull SNAT implementation itself has most of the characteristics of a "firewall".
Sure, but you should recognize that that's the same as saying a stateful SNAT implementation is an incomplete stateful firewall.
If your goal is to use private addresses, you should use NAT. The point is that if your goal is security, then you should configure a firewall.
Don't expect software that isn't designed to provide you security to provide you with any security.
SNAT can be used to mask source IP and that can absolutely be utilized strategically as a layer of "security".
What's represents a "good chance" the router is so grossly misconfigured as to allow inbound traffic no destined for the IP assigned to the WAN interface to be routed to one of the internal interfaces? I wouldn't be surprised, but what's a "good chance"? Is there data on this?
A typical, correctly configured SNAT implementation would most likely have the characteristics commonly attributed to a "firewall". An incorrectly configured network device may not have the characteristics commonly attributed to a "firewall", regardless of its ability to actually inspect and drop packets(which just about every commonly used OS network stack can do out of the box).
But even an SNAT implementation without typical "firewall" characteristics has intrinsic characteristics related to security; such as source IP masking. Which doesn't even need to be private.
This is just not correct. NAT and firewall are simply orthogonal concepts and can and often are deployed separately. A simple example is your average small SOHO router, which usually has NAT but quite a lot of them lack a firewall.
But in that case, it's very obvious because your access to the WAN side of your router won't work from anywhere except the router itself.
I like this "fail-secure" nature of NAT. If your firewall fails on a network with globally-routable IPv6 addresses, it might not be so obvious as traffic might still flow through.
This is a major problem to me before I'd go wholesale IPv6 at home as the primary way I address and connect to hosts
I have IPv6 enabled, but it's just all defaults. My traffic is going out over the internet on IPv6, my home automation stuff in the house using Matter is on IPv6, but for the few server-types that I have in the house they are still identifiable by me by their IPv4, and my addressing to get into my network from outside is via my ISP's IPv4 address
There really needs to be a universal way to bring IPv6 addresses to your ISP, so they're portable like a phone number. Both so that I can take them with me if I switch providers and so that my ISP can't arbitrarily change them from underneath me
So on options is to assign yourself an [RFC 4193](https://datatracker.ietf.org/doc/html/rfc4193) fc00::/7 random prefix that you use for local routing that is stable, while the ISP prefix can be used for global routing.
Then you don't need to renumber your local network regardless of what your ISP does.
If you want stable global addresses, you should request an AS number and prefix, and choose a provider that allows you to announce it with BGP.
Lots of people don't have much choice.
Frankly, my IoT washing machine having a public IP address sounds like it'll get shut off when I don't let it online or don't pay my subscription fee.
Yeah but it's not like IPv4 is any better at giving you a stable public address.
There is. It's "Provider-Independent" address space.
It's used sparingly because widespread use of it would explode the size of routing tables.
I think you could also "simply" [0] become your own AS/LIR/whatever and negotiate with your ISP to route your prefix/subnet/whatever to your site (or some box in a colo somewhere that you attach to your site with some sort of tunnel).
[0] It is my understanding that it is often not at all simple to do this.
IPv6 is already a nightmare for dealing with scammers and spammers. It's very often I get weirdly blocked because someone has abused my ISP's (AT&T) IPv6 block that I'm on and Wikipedia or whoever has blocked an entire /48 or something and it's virtually impossible to get a delegation outside of that range
You have two layers of indirection and one layer of security. If you failed to configure your firewall correctly, you would be better off without NAT because you would become aware of it quicker and not rely on NAT.
NAT doesn't really do anything other than address conservation because of NAT-punching techniques like STUN/TURN/UPnP, which are nessisary because NAT's features are bugs.
That's not true. When you configure just NAT (with e.g. nftables on Linux), the NATed devices are still reachable from the outside, you just have to add an entry to your routing table to reach that internal address space using the router.
This is not quite correct. You have two simple options for avoiding this: DNS and SLAAC. By giving all of your hosts dns names you don’t have to care about the individual addresses much. If they change just update the dns zone.
The second is to configure a Unique Local Address for each host using SLAAC. Have your router announce a prefix inside of fd00::/7 so that every one of your computers ends up with a private address as well as the public one. This is like using a reserved private address in IPv4, such as 10.0.0.0/8, except that there are a lot more possible networks. There is only one 10.0.0.0/8, but the convention with IPv6 ULAs is to generate 40 random bits and use them to make a /40. Add 16 more bits for a subnet id to create a /64 that your router will advertise as a prefix. This is probably overkill for most of us, but it does enable us to merge networks without causing address collisions. You can keep using them no matter what happens. Even changing ISP won't change these addresses.
Of course the third option is to buy IP transit service instead of internet access service. You can then go to your local RIR and ask them to assign you your own address block. Announcing that address block using BGP gives you a permanent block of routable addresses that follows you from ISP to ISP. But most people find that to be a bit of a hassle compared to consumer–grade internet service.
"just" update the zone? Yikes. I prefer to not take that downtime in the first place. (And I know from experience, I've written hooks for dhcpcd that automatically reconfigure my zone file, firewall rules, rad.conf, etc, if I get a new network prefix! But I don't pretend that this is a workable approach for everyone.)
> The second is to configure a Unique Local Address for each host using SLAAC
Yes, this is the way. Where you used to use RFC1918 addresses, just use ULA. It's simple and fits the mental model you used to have with IPv4. You don't even need NAT, just give both the GUA and ULA addresses to each host, and use the ULA everywhere you want LAN-like semantics.
Also:
- There are 16 172.{16-31}.0.0/16s (I used 172.23 because Docker uses one of these)
- There are 256 192.168.{0-255}.0/8s
And that’s just what RFC1918 gives us. There are other private subnets defined in newer RFCs.
I like IPv6 but it caused issues with browsers accepting my Letsencrypt certs on my website, so my website is now IPv4 only.
“Announcing that address block using BGP gives you a permanent block of routable addresses that follows you from ISP to ISP.”
Enough people have done this that BGP networking has become a real mess at the ISP level. Can BGP really handle every person in the world doing this?
> Can BGP really handle every person in the world doing this?
Eh, probably not. I did say that it wasn’t for everyone. You have to fill out a form, and then they announce to the world that you did it. And if you configure your BGP announcements wrong you’ll get laughed at by everyone who watches those things. Most people can’t handle it.
On the other hand, the VP of Network Operations at the ISP I used once promised that they’ll honor BGP announcements even from residential customers. I guess once it’s automated that it doesn’t cost them anything extra. Could be a fun hobby.
And if enough people do it then we can simply improve BGP. Anything we invent we can improve, right?
You talk about NAT like it's a single thing: it is not. There are at least three major varieties of NAT:
* https://blog.ipspace.net/2011/12/is-nat-security-feature/
See also various 'cones' that add complexity to getting things to work (and for which kludges like ICE/TURN/etc had to be invented):
* https://en.wikipedia.org/wiki/Network_address_translation#Me...
See also RFC 4787 which distinguishes between NAT mapping and NAT filtering. Also, also see perhaps "NAT Traversal Mess":
Because your devices are routable. You can’t be on the Internet without an IP. They just have some ephemeral addresses. But randomizing port numbers (that is NAT) is not a good security mechanism.
It should also be noted that "NAT" is not some monolithic thing either, there are three 'major' varieties:
That is good for you, but given the option between an address scheme that requires a proxy and one that does not, I would prefer the latter.
>I can have a both a firewall and a NAT. The two layers are better than one because at least my address is shouldn't be routable even if I failed to configure my firewall correctly.
Why? NAT is a network tool. Firewall is a security control.
If you don't listen to public ports on IPv4, then there is no point in touting any of the benefits of IPv4. Even if you think NAT is good, you're not using it in the first place so why care about it?
You basically ruined your entire case with that sentence.
Just because you don't shouldn't mean other people get denied this.
Expanding on this. NAT as deployed in most soho/residential settings requires a stateful firewall to track connections + port mapping logic.A stateful firewall is also used for IPv6 edge security and using the same basic posture (out allow, in established/related only) except the only difference is it isn't also doing an address mapping. Nobody is out there saying folks should run a wide open IPv6 edge, and as far as I'm aware no one is shipping IPv6 ready consumer routers that do that (but I'm prepared to be proven wrong in the responses).
This is a feature not a flaw. The average person doesn't have anything acting as a server, and that's a good thing, because the only servers they'd have would be embedded garbage in poorly maintained or completely abandoned IOT devices with incompetent code that should not be publicly exposed, ever, in anything but a call out model.
Of course if the router is misconfigured, then all bets are off. But that’s true regardless of IPv4 vs IPv6, because people will just compromise your router first and use that as a launch pad for the rest of your network. Just like to do today with plenty of old residential routers.
I want to be running a proxy in that scenario, because I don't want any of it accidentally exposed.
> It's called a firewall. You want a firewall. IPv6 also has a firewall. NAT is not a firewall. NAT is usually configured as part of your firewall, but is not a firewall.
Yes, but it's arguably helpful to have configuration mistakes still leave your internal network unexposed. It's harder to accidentally expose resources when your ISP won't route to them.
> What are you supposed to do with a /8? Do you have several million computers?
Except you can subnet an IPv4 /8. You can't subnet an IPv6 /64. For whatever stupid reason, and despite having 18 quintillion available addresses in a /64, you can't actually do anything useful with it other than yeet a bunch of devices on the same LAN segment.
(At least on pfSense, and when I looked into it some, that's apparently IPv6 design for some reason)
With a IPv6 /64 you can (1) NAT, or (2) better, subnet it and use DHCPv6.
The only thing significant about /64 is that’s the smallest unit for SLAAC.
...which means you can't subnet it because you have to assume SLAAC might happen since that's the only thing ipv6 requires. Ergo, an ISP only giving you a /64 means you have to nat if you want subnets, and if you have to nat why wouldn't you use ipv4 instead where it's so much simpler?
It is not a bad thing actually.
At the same time SLAAC is the reason your ISP doesn't give you a /128.
Absolutely nothing, because the private IPs behind the NAT are agnostic of the public IP.
They are also much shorter. [https://en.wikipedia.org/wiki/Link-local_address]
One really nice thing about IPv6 is you can (and do) have many addresses, all of which work.
for example, you can add a manual fe80::5 address to one machine, and fe80::9 on another - and use those to access those machines on the local network. And not have to worry about that being externally addressable, or having conflicts, etc.
And they won't change when your external addresses change either (unless there is some weird software bug in your OS or something).
Though you probably want to use a unique local address range instead [https://en.wikipedia.org/wiki/Unique_local_address] as they're more equivalent to the 10.0.0.0/16 type behavior you're expecting.
> What are you supposed to do with a /8? Do you have several million computers?
The /8 was for private addresses, so "free" and uncontested, while the /64 is a public resource. Looking at it as extraneous or over provided is understandable IMHO, even if mathematically it's not supposed to get depleted.
At least it's not doing anything helpful for OP.
Basically I had no choice but to redo my home network if I wanted to use my new work laptop at home (and I work 100% remote).
[0] Or whatever the netmask actually is. I'm never sure about the 172.16.x.x space.
And if you ever need to use another VPN that also clashes on 10.x, you can do the same thing but map that one into 2001:db8:a:c::/96. Then you've got 2001:db8:a:b::10.1.2.3 and 2001:db8:a:c::10.1.2.3, neither of which clash with either each other or your 10.1.2.3.
Most ISP’s implement IPv6 by using the single IPv4 address as a v6 prefix. This results in the entire LAN needing to change local addresses every time the public IP changes. In practice this means a single brief power outage causes hundreds of devices to break instead of none.
Generally speaking ipv6 is useless for most home network users.
Overlapping 10/8 with corporate networks is not a problem, wireguard has solved this in all cases I’ve run into.
> It's called a firewall. You want a firewall. IPv6 also has a firewall. NAT is not a firewall.
Security folks call those techniques "hole punching" but they are how NAT is expected to work.
I mean thats not actually true, uPnP will open ports up, as will misconfiguration.
The firewall is still the same in ipv6 vs 4, and has the same problems.
Not quite. Using UPnP, any host on your internal network can open a port for any other host. You may be thinking of NAT-PMP.
Additionally, by default UPnP mappings don't expire (unlike NAT-PMP mappings), so if a host crashes with an open port and your ESP32 inherits its IPv4 address, it will be exposed to the Internet.
Thank you. I never considered the reused address vulnerability.
To my internal net: nothing. All my internal addresses stay the same. All my firewall settings remain the same. Just to the outside world I come from elsewhere (which is good for my privacy, not sufficient obviously, though)
However if my IPv6 prefix changes all my IP based access control, which is a layer I use to limit what Internet of Shit devices can do, breaks. I could go to fe80 addresses for my local network, but those won't work across different network segments.
This prevents clashing subnets when using VPN like it sometimes happens with IPv4.
That's great until you need to connect to a work/client VPN that decided to also use 10.0.0.0/8.
> - Every host routable from anywhere on the Internet? No thanks. Maybe I've been irreparably corrupted by being behind NAT for too long but I like the idea of a gateway between my well kept garden and the jungle and my network topology being hidden.
Even on IPv4, having normal addresses for all your computers makes life so much nicer. Perhaps-trivial example, but one that matters to me: if two people live in one house and a third person lives in a different house, can they all play a network game together? IPv4 sucks at this.
There's numerous other reserved IPv4 blocks that can be used: https://en.wikipedia.org/wiki/Reserved_IP_addresses#IPv4. Would definitely not recommend to use 10/8 for private networks.
Using 2 different classes has been a pretty common setup for wifi and wireless in my experience
> - My ISP gives me a /64, what am I supposed to do with that anyways?
There is recommendation (SHOULD, not MUST in RFC lingo) for ISPs to provide at least /56 to clients, but most domestic ISPs ignore this recommendation.
> - What happens if my ISP decides to change my prefix ?
Your ISP has paid 40€ for your IPv4 address. That's a cost they're most probably passing on to you.
> Every host routable from anywhere on the Internet? No thanks.
Every time you start a videoconference, there is a couple of seconds' pause while the peers perform NAT traversal.
fd00::1 is pretty easy to remember. It's your network, give yourself a sane and short prefix.
With IPv4 I can easily remember 10.0.0.0/8 and 192.168.0.0/16, but I can't remember the other one off the top of my head. (172.16.0.0/12 I think?). Multicast is 224.x.x.x/x IIRC, but definitely need to look that one up when I need it.
IPv6 has SO many special networks. Network. Public. Multicast. Link local. (Which isn't like an IPv4 link local, but apparently it can actually be on the LAN? IDK - I was just learning about it earlier today.) And every interface seems to have about 5 different addresses of each type.
It's like the difference between HTML and a strictly typed language. Permissiveness and flexibility is both a blessing and a curse. As with a lot of things, which thing it is in any given situation depends greatly on the situation.
There is no point in your network having sequential addresses, so you don’t need DHCP; routers advertise configuration, clients know where to look for it.
IPv6 is amazing, if you let it handle connectivity without trying to micromanage it.
Remembering IP addresses... How quaint!
And one still needs to pay attention for ipv4, so what is the benefit? A simultaneous half-vigilant, half-careless stance is not workable.
Even if you have your own DNS server out there somewhere, you still need to allow a bit of DNS hijacking from your ISP in order to receive that verification SMS and enter the code into the ISP's log-in page.
DNS is a great thing, but just too much of a pain to configure.
Important part is knowing there are special networks.
IPv4 has those exact same ones: link-local (169.254/16), multicast (224/4), public, private (RFC 1918).
* https://en.wikipedia.org/wiki/Reserved_IP_addresses
IPv6 is (IMHO) simpler: 2001::/32 and anything else (either link-local (fe80), multicast (ff00), and ULA (fc)). So either it starts with a "2" or an "f".
You might also be unaware of the fact that network interfaces can usually be assigned multiple IPv4 addresses, just like they can be assigned multiple IPv6 addresses.
> ...the application does not have to figure out which one it has to use.
You might be surprised to learn that that's the job of the routing table on the system. Applications can influence the choices made by the system by binding to a specific source address, but the default behavior used by nearly everything is to let the system handle all that for you.
[0] You appear to be unaware that multicast addresses aren't assigned to a host. I suspect you're unaware that IPv6 removed the special-case "broadcast" address. It's now treated as what it actually is; the "all hosts" multicast address.
It's time for IPv5, I know its been taken so may be IPv7.
ipv6 just gives you two configurations to maintain, two firewalls to write rules for and cross-leaks that are hard to understand.
I make my internal network ipv4 only, I have a lovable static config, one firewall to maintain. I also use vlans to separate into "can get out", "can only get out through a whitelist proxy", and "can't get out ever". and I am very happy.
I just don't understand how people can just plug every device they own into a promiscuous ipv4 and ipv6 router and contribute to profiling, television snooping, vacuum cleaner house mapping, data leaks, botnets and more...
10/8 is great until two organizations with 10.0.0.0/24 in their OSPF or IS-IS topologies are brought together via a merger/acquisition. Then you can end up with NAT with-in an organization itself. (Internal split-horizon DNS here we come.)
Bangs head against desk
NAT per se does not prevent an outside host from connecting to a host on your local network.
Yep, and a firewall per se does not prevent an outside host from connecting to a host on your local network. You can bang your head all day long, the side effect of NAT is to only allow incoming traffic that refers to an established connection that was initiated from the local network. How is this different from a firewall that does
Allow established, related
Allow outbound
Deny inbound
If it did then you might have a point, but since it doesn't it's very different from a firewall that's configured to do that.
That's the primary function of NAT, not a side effect.
> It doesn't filter incoming traffic.
Of course it does, it drops any incoming traffic for which it cannot find a corresponding connection. How is this not a filter?
I know that internally these two are vastly different. The reality is that NAT is used as protection for millions of home networks.
Well, no. They do ignore them, but that's not effectively a drop. It's an ignore. It just means that they don't edit the packet. Whether it gets dropped or not depends completely on the routing and firewalling parts of the router.
People do generally expect a NATing router to firewall inbound connections, but it's important to realize that you won't get that behavior from NAT. You must have a firewall, which is a separate thing.
On a publicly routed PC, I can call `listen` and an outside host can connect to me.
On a PC behind a NAT - if I don't set up port forwarding - I can call `listen` and nobody from outside can connect to me.
So one could say, going from publicy routed to behind a NAT means that only allowed incoming connections are possible. Or am I missing something and you can really, from the outside, open a connection to a PC on a residential network which is behind a simple NAT (TCP server listening on that PC)?
The only caveat is that if you're using RFC1918, it greatly limits who can connect -- only your ISP, or another customer connected to the same shared VLAN your router is, or anyone that can physically attach to that network (or anybody in a position to order, blackmail or social engineer those three groups or their employees) can do it, because they're the only people that can set a route to your router for RFC1918 destinations.
Other than that, the connection will just head right on through your router. NAT's whole thing is to change the source address of your outbound connections. Inbound ones (when they don't match port forward rules) are ignored by it, which means they get routed by the router in exactly the same way they would if the router wasn't doing NAT.
At best you could argue that RFC1918 blocks connections, which would be somewhat closer to true, but... well, it doesn't. If you actually want to stop all connections from outside your network, you've always had to do it with a firewall on the router.
And of course, I said "if". You can NAT on public IP space. On residential connections you're unlikely to have public IP space on v4, but that's just a consequence of v4 being exhausted.
There's a ton of things you can do to cut down on the scan space for v6, but it's still far huger than v4 can be.
I share some of the same thoughts
IPv6 should be optional, not mandatory
I disable IPv6 whenever and wherever I can
Gateway is always IPv4 only
No "smartphone" gets direct connection to the internet
IPv6 can be useful. For example, cjdns
I like having the option to use it, but it should not be mandatory
At least here in the U.S., my observation has been it's usually a bit faster and has more efficient routes than IPv4. I assume part of that is using newer equipment and architecture than practical for IPv4 and ability to have more granular routes.
I regularly see 1-2ms improvement to first hop outside my ISP network (10ms vs 12ms)
Remembering addresses is a solved problem with DNS.
Gee thanks, network experts, for solving a problem I don't have and making me pay for it!
Never understood why they decided to include letters instead of keeping it numeric.
Hell, going from 199.120.121.122 to 199.120.121.122.123 will have expanded IPv4 by 254 times. It took us, what? 40 years to exhaust Ipv4... Just increasing it by 254 alone is insane large amount.
Belgium used this solution for their number plates They used to have a 6 letters/digit mix. Like abc-001 type of number plate. It started to run out, so they simply created a expansion, so new number plates started with 1-abc-001 in 2010, ... and in 2021 did 2-abc-def ( they did not run out of 1, they seem to simply use the first number to indicate the decade more and more). At that rate, Belgium will run out of numbers in they year 11990 ...
Ipv4 is easy to work with, easy to remember, write down, read ... Ipv6 is always a struggle. And yea, the idea that every device may need its own IP from your provider, is just insane.
I have so much more issues configuring things with IPv6, vs just basic IPv4+NATS. Its simply, its easy...
And maybe some people do not have this issue, but our provider gives DYNAMIC IPv6, so the pre-fix keeps altering! What makes configuring things on a NAS even more hell.
O and that :: range modifier is so fun. And the whole pre-fix and post-fix structure...
I hate it. Its complex for my little brain as i do not work daily with it, and whenever i need to deal with Ipv6, i need to relearn the quirks of it every time because of issues like the whole pre-fix/post-fix, dynamic pre-fix etc. Where as IPv4 ... so easy.
In it's original design, SIPP, the design that was chosen for IPng had 'only' 64-bits, but it was decided that it would be impossible do another transition, and going to 128 would be better future-proofing:
* https://datatracker.ietf.org/doc/html/rfc1752#section-9
So 199.120.121.122 could have grown to 199.120.121.122.152.183.166.197, which I do not think would have made a practical difference to those who complain about "hard to remember" addresses.
And it took 40 years to exhaust IPv4 because NAT was invented (RFC 1631), and now we're stuck with that kludge and have to have all sorts of workaround for it (ICE/TURN/STUN). IMHO it has also has contributed to the centralization of the Internet because doing P2P is just a pain in the ass.
But I agree, using a reserved byte to select internet, say 0 for original, next two hundred for each region, with the rest for planets/moons/nearby stars, would have been easier to understand.
Disagree. We are trained on numbers from kindergarten. It's used everywhere (e.g. see a number, store it in short-term memory and input it into calculator). Hex digits are completely different and we don't have developer neural paths for that. They are also unpronounceable.
For example, I'd prefer c0a8.0001 to 192.168.0.1/16 notation. The limitation is that the netmask delimiter can only split by nibble.
Remember, mate, with a /64 you can host your own ISP. You can finally have real Internet access! (Oh, wait -- it's not actually your /64 and your local ISP[s] wouldn't route it to you if it were, so you really can't.)
> - Every host routable from anywhere on the Internet? No thanks. Maybe I've been irreparably corrupted by being behind NAT for too long but I like the idea of a gateway between my well kept garden and the jungle and my network topology being hidden.
Oh, come on. Just look around. Almost everyone here agrees: NAT isn't a security function. Furthermore: NAT is literally the devil and has been for all of the decades you've been using it. Just think of all the stuff it breaks! Like FTP! (Remember how broken FTP was with NAT back in 1995? Or, *shudder*, h.323?)
Besides, with a /64, you can even have every computer on your network changing addresses for every IP connection! Doesn't that kind of obscurity sound nice? (Except... No, that doesn't sound nice at all. That just sounds bizarre and weird -- like dancing about architecture, or maybe some analogy about babies and bathwater.)
> - Stateless auto configuration. What ? No, no, I want my ducks neatly in a row, not wandering about. Again maybe my brain is rotten from years of DHCP usage but yes, I want stateful configuration and I want all devices on my network to automatically use my internal DNS server thank you very much.
Have you ever considered the concept of giving each machine two different IPv6 addresses? One for you to control, and one for your ISP to be in charge of. That'd be quite lovely, wouldn't it? (Except: Now you have two problems.)
> - It's hard to remember IPv6 addresses. The prospect of reconfiguring all my router and firewall rules looks rather painful.
Yeah, well. Uh. Have you tried looking into using ULA addresses like fe80::? (It's awesome! It's got all the hypothetical network convergence problems that an RFC 1918 10/8 has with which to bite you in the mysterious future, except it's also hexadecimal! And unlike the grossly prevalent DHCP system that your 10/8 LAN uses today, nobody can agree on how to centrally assign these addresses to devices!)
> - What happens if my ISP decides to change my prefix ? How do my routing rules need to change? I have no idea.
Look, man. Let me just move these goalposts for you. The real problem here is that people, like you, need to adopt IPv6. So adopt it already. Your router's implicitly always-on stateful firewall will just take care of it, just like it has almost certainly both incidentally and irrevocably done for your entire history of using NAT with IPv4. And the advantage to you is... you have that big, beautiful /64 to play with however you want (except: it isn't yours, so you don't), free of the chains of that ugly hack of NAT.
(See? That wasn't so hard! The goalposts are heavy, but they can still be moved easily-enough. These new chains are better than the old chains, anyway. The chains of IPv4 NAT were getting a little bit old and dusty, and learning which /64 your ISP will decide to number your LAN with this week is like opening a surprise box! Unless your ISP provides a /56 or something instead! Don't you like surprises? Hey, did I mention ULA? It's always important to mention ULA at least thrice because maybe you want at least two sets of LAN addresses for everything!
(All snark aside: ULA+DHCP+local NAT doesn't sound so bad at all. fd00::3 instead of 10.0.0.3? Gateway at fd00::1 instead of 10.0.0.1? Singular static LAN addresses if we feel like it -- without them being world-known, and regardless of which residential ISP we're using at the moment? People can get used to that. And it would at least present a familiar set of problems that would respond to a familiar set of solutions -- plus, with bonus nachos consisting of a whole dynamic /64 to play with if we ever feel like using that for some reason.
But AFAICT nobody does it that way because NAT is in and of itself some kind of evil thing even when it is under our direct control, so we're just stuffed. Thus, instead of local NAT, we get some combination of prefix bingo, global per-device identifiers or bizarro randomness, and/or overlayed logical networks with local ULA+public Internet addresses for the same friggin' doorbell.
And that shit is simply weird.
As a response to the weirdness, we get the resultant and inevitable pushback that all weird shit deserves.))
CGNAT is a different discussion entirely. Neither the presence nor absence of upstream CGNAT changes my thoughts on locally-administrated NAT for my own LAN in IPv6 land.
From my own perspective: I've been hearing people complain about local one-to-many NAT for a very long time, starting 30 or so years ago when fairly-regular people started introducing internet connections to their small networks.
These days, I hear about IPv6 being awesome mostly because it can used to eliminate the need for one-to-many NAT at the local border.
And that sounds great, in concept, except: This elimination introduces new issues that people didn't experience in their previous world of local NAT.
---
CGNAT is its own thing that was broadly introduced relatively recently. It can be similar in operation, but is generally very dissimilar in terms of scale and our ability to control its operation as end-users.
And people know it's different. We even use a different term to disambiguate it from other, more-local, types of NAT that are popularly implemented at the border between their LAN and the Internet: We call one of these things "NAT," and the other of these things "CGNAT".
---
And to be very clear: If I've ever meant to write about CGNAT, then I'd have done so -- and it would be obvious.
I'm very reluctant to defend a position that I have not presented, as entertaining such strawman arguments brings me to feel the opposite of satisfaction.
I'm richly disinterested in such discourse.
And it means you left a very important argument in favor of IPv6 unmentioned.
> This elimination introduces new issues that people didn't experience in their previous world of local NAT.
I didn't see you list any downsides of removing NAT in your earlier post, just mock the upsides. But maybe I misinterpreted part of the sarcasm.
This isn't ignorance. This is an example of a little knowledge is a dangerous thing.
Ignorance is the internet just works the way it's meant to work for everyone. That's only practically possible with IPv6 these days. Your limited use case and privileged circumstances (ie. you even get a publicly routable v4 address) do not mean anything for someone who just wants things to work.
Obvious disclaimer: This is a sample size of 1, and an anecdote is not data, yada yada. I'm not involved in academia, and have no insight into the adoption of IPv6 in CompSci networking curricula on a broader level.
As of 2024, IPv6 deployment in France was >97% mobile and >98% residential due to not being required for obtaining a 5G radio license (and then v6 simply carried downward to being available on 4G) + every ISP that provides FTTH also providing v6.
https://www.arcep.fr/fileadmin/reprise/observatoire/ipv6/Arc...
Over here IPv6 JustWorks to the point of absolute boredom.
But penetration there is just about 15% or so :/
I just signed with macOS Preview, applied some random noise filter and used a one-off online fax service. ¯\_(ツ)_/¯
what's the argument behind that? are they scared they might configure their firewall bad and have no NAT to safe them from accidentally making all devices public?
People don't understand something and just apply the most annoying rule possible.
The craziest one I saw in Germany was "cookies are allowed, localStorage is not", that was for our app. CTO overrode the CISO on the spot and called him an idiot for making rules he doesn't understand. Interesting day.
I've heard some ex-post justifications, make of them what you will: Existing infrastructure like firewalls, VPNs and routers might not be able to handle IPv6 properly. Address distribution in IPv6 is unpredictable. No inhouse knowledge of IPv6. Everything has an address in IPv6, so the whole internet can access it. No NAT in IPv6, so it is insecure. IPv6 makes things slow.
Many of the big benefits are things that don’t deliver anything that folks are lacking. You also need to understand how you fit in the overall universe more.
My home network is dual-stack these days, but because my IPv6 prefix is dynamically delegated by my ISP, I actually use site-private IPv6 addresses for all my internal servers and infrastructure.
The thing is though, I don’t even need IPv6. Comcast Business broke my delegation for six+ months and I literally didn’t even notice.
IPv6 tried to do way too much. The second system syndrome was strong. It’s no wonder folks are annoyed at the complexity, and as long as IPv4 continues to works for them, they aren’t particularly pressed to adopt it.
And I've been in corporate IT networks with mergers/acquisitions where both organizations involved had 10.0.0.0/24. Ever have NAT inside a company? Fun stuff. (Thrown in some internal-only split-horizon DNS too.)
Then there's the fact that in the COVID period we had IPs for VPN clients (172.*) in the same range as what some developers used for their Docker stuff. Hilarity.
Heck, I couldnt even see which prefix I was handled, nor could I see any ipv6 address anywhere in the gui. This was with a self hosted up to date controller though. YMMV.
That’s a pretty good benefit, I hadn’t considered that!
Part of it being that a lot of ISP's don't have static prefixes, they do get rotated pretty often and have no guarantee of CIDR size that you're going to get. By default my ISP will only give a single /64. You have to go out of your way to request more subnets and there's no guarantee that the ISP will honor that request.
It's really problematic to try and base a non trivial network setup, when you have no guarantee of how many subnets you can run. Today I've got 256. Tomorrow it might be 16. Or 2. Maybe just 1 again. ISP's can be weird when they smell monetization dollars in the water.
So I have to run a ULA in parallel to the publicly accessible networks specifically for internal routing, and then use a DNS server to try and correct it. Which works great! ...except when you run into this little niche operating system called Android. Which by default doesn't obey a network provided DNS server if you've got privacy DNS enabled. So if I've got guests over and I want them on a network in my place to access some sort of internal resource, then I've got to walk them through disabling privacy DNS.
Either that or I need to go out and buy a domain... for my internal network...and then get a TLS certification for my private internal domain.
I get how IPv6 can be great. But a lot of the advantages are also overhead I don't want to deal with.
Short hand is a good example; I've lost count at the number of times I've typo'd short hand addresses because my eyes skip over a colon. At this point I've gotten into the habit of just writing out the whole address, leading 0's included because the time saved from not making a mistake reading the address often faster overall then making mistakes with shorthand.
This also sounds like it would be a problem for v4? I'm not clear on how this is a v6 problem. If I'm picturing it correctly, it's a difference of handing the guests a local v4 address vs disabling privacy DNS and handing them a DNS name. I'd think the latter would be easier
Using a public domain for TLS certs for private networking is pretty standard in /r/selfhosted and /r/homelab at least.
Fair point on ISPs handing out /64 prefixes, but this is the first I've heard of them varying the prefix length once you know what you've got. I don't doubt it though
TBF, if you are on HN that should be extremely simple for you. I use a subdomain of my primary email domain I own, and use LetsEncrypt to issue TLS certs on my internal network. Well beyond the means of my mom and sister, but probably pretty easy for most people here.
It's almost a self-inflicted tragedy of the commons or reverse network-effect.
Adopting IPv6 doesn't alleviate the pain of IPv4 exhaustion if you still need to support dual-stack.
1. Use IPv6 which works and goes directly to the virtual machine because each virtual machine grabs its own address from one of my 18446744073709551616 addresses.
2. Use IPv4 and either have to do a jumphost or do port forwarding, giving each virtual machine its own port which forwards to port 22 on the virtual machine.
3. Use a VPN.
Also being able to generate unique ULA subnets is super nice.
A lot of servers expose something public so they can be found. Otherwise what's the point of being publicly accessible?
1. You listen on IPv4 and someone probes all the IPv4 space and your server announces "Hi, I am web123.example.com" or similar in its responsible
2. You have HTTPS on the server and the HTTPS address ends up in the certificate transparency logs.
3. You have a public service on that server and announce the address somewhere.
But when you have billions of IP addresses, why does SSH need to listen on the same address as HTTPS or anything you're running publicly? It's also infeasible to probe the entirety of IPv6 space the way you can probe all of IPv4, even though we're only assigning addresses in 3/65535 of it right now.
I mean, yes, you'll get a constant stream of them on IPv4, but why would you run a server on v4 unless you absolutely needed to? The address space is so small you can scan every IP in 5 minutes per port, and if you have my v4 address you can enumerate every single server I'm running just by scanning 65k ports.
Meanwhile, on v6, even the latter of those takes a thousand years. How would people even find the server?
There is a talk by Dmitriy Melnik at RIPE 91 about the costs for ISPs to not adopt ipv6 vs to adopt ipv6 (relevant stuff starts at 9:55).
https://ripe91.ripe.net/programme/meeting-plan/sessions/37/8...
https://www.reddit.com/r/openwrt/comments/1lopamn/current_hi...
Tell that to my fixed line provider, with their CGNAT ... And its just about every provider in Germany pulling that crap. O, and dynamic IPv6 pre-fix also, because can't have you run any servers!
Yes, plenty of ways to bypass it but when you have ISP's still stuck in 1990's attitude, with dynamic IPv4/IPv6, limited upload (1/3 to 1/5 of your download), etc ...
Sure it does: the more server-side stuff has IPv6 the fewer IPv4 addresses you need.
If you have money (or were around early in the IPv4 land grab) you have plenty of IPv4 addresses so can give each customer one to for NATing. But if you don't have money to spend (many community-based ISPs) you have to start sharing addresses (16:1 to 64:1 is common in MAP-T deployments). You also have to spend CapEx on CG-NAT hardware to handle traffic loads.
Some of the highest bandwidth loads on the Internet are for video, and Youtube/Google, Netflix, and MetaBook all support IPv6: that's a lot of load that can skip the CG-NAT if the client is given a IPv6 address.
If you can go from 1:1 to 16:1 (or higher) because so few things use IPv4 that means every ISPs can reduce their legacy addressing needs.
Tell that to everyone who is behind CG-NAT and has issues with (e.g.) video games. Or all the (small(er)) ISPs that have to layout CapEx for translation boxes.
Tech finds a way…
Peer to Peer games with no central authority would be so rife with cheating that you’d only ever want to play with friends, not strangers. That sucks!
Back in the the day RtCW had a server anyone could run and you could give out the address:
* https://en.wikipedia.org/wiki/Return_to_Castle_Wolfenstein
There was a server that a ISP / cable company in the southern US ran that I participate in and it was a great community with many regulars.
P2P can be awesome with the right peers.
Is that all IPV4s fault? I don't think so. But it complicates things
All of these issues are solved by having a central server for both players to connect to. Whether that server is owned by the game's publisher or by an open-source community is irrelevant from a technology standpoint. However, the prevalence of IPv4 networks and stateful NAT firewalls is relevant because it privileges those central servers over true peer-to-peer connections.
If you only care about gaming with friends, then peer to peer is an excellent way to do that (assuming the game doesn't have any synchronization issues, which some peer to peer games do).
That just reminded me of a peer protocol I worked on a long time ago that used other hosts to try to figure out which hosts were getting translated. Kind of like a reverse TOR. If that was detected, the better peering hosts would send them each other's local and public addresses so they could start sending UDP packets to each other, because the NAT devices wouldn't expect the TCP handshake first and so while the first few rounds didn't make it through, it caused the NAT device(s) to create the table entries for itself.
Was it Hamachi that was the old IPX-over-IP tunneling? I'm fairly sure it used similar tricks. IPX-over-IP is also done on DOSBOX, which incidentally made it possible to play Master of Orion 2 with friends in other continents.
Sounds similar to STUN, really.
Does make me chuckle that so many people had to be working around NAT for so long and then people are like "NAT is way better than the thing that makes us not have to deal with the problem at all." Just had a bit of NAT PTSD remembering an unrelated, but livid argument between some network teams about how a tool defeating their NAT policies was malware. They had overlapping 10.x.y.z blocks, because of course they did :)
Thus, CG Nat was invented so that IPv6 could talk to IPv4 and get the information from it.
Because all of the www is in IPv6, and cgnat actually excuses for ipv4 cable users to use the bedrock internet servers and services?
Bullshit. Cgnat is a hack for ipv6 to talk to the ipv4 universe.
Because if there were magically enough iov4 addresses for mobiles, would cgnat exist? No, it wouldn't.
IPv6 has arguably done more to counteract market forces related to IPv4 address exhaustion.
When your washing machine, fridge, etc all come with ipv6 5g modems is when your house becomes part of the future IT battlescape between lots of different entities that do not wish you well.
different routers have different options, but all of them have come with a pretty strong firewall out of the box, turned on by default, for the last 10 years.
They get better network management.
They do if they have applications, such as Xbox/PS gaming applications, broken VoIP in gaming lobbies, failure of SIP client to punch through etc. And if an ISP does not have, or cannot afford, to get enough IPv4 to hand each of their customers at least one to assign to the CPE's WAN port, you're now talking about CG-NAT, which a whole other level of breakage.
It’s genuinely disheartening to see so many people here not even begin to try to understand how much we’re missing by not having effortless end-to-end connectivity, in favor of expensive cloud services. This literally used to be what the “Internet” is - we’re definitionally not on one without this.
* The internet
* Linux servers
* Automation
I get your point, but it falls on deaf ears to me since most people don’t feel the benefits until some passionate nerd makes something that scratches an itch.
For a practical example: peer-to-peer sharing like Airdrop is much easier to implement in a world with ipv6.
And without firewalls. Unfortunately this world does not exist.
Does the world at large care? No.
Do I care? Yes.
Do my users care? Yes, albeit indirectly.
Does my organization care? Yes, in the sense that it removes friction from what it needs the employees to do.
And that's all the justification that's needed, I'd say. The world very clearly doesn't need to revolve around what I love for IPv6 to be a good thing.
No One believes us on hacker News. It feels very gaslighty. I have never talked to an IT engineer in person that thought IP version 6 in the data center or in the corporate network was a good idea.
This is just further proof that university educations are still not job training. The sooner we disabuse ourselves of that perception the better off society will be.
Higher education is about creating a breadth of knowledge, not specific marketable skills. CompSci is a research field, not job training.
If your friend wanted to learn specific job skills a technical college would be the appropriate setting.
I realize this misperception is perpetuated by the job market but I’m still not surprised at the education provided by UCI and don’t fault them for providing it.
Separate from that, deliberate decisions were made to make it a "clean slate" without consideration for existing ipv4 hosts. Guess they were hoping the separate stacks would go away eventually, but in hindsight, no way.
IPv6 isn't all that complicated for most common use cases. Its fundamental concepts and rules are simple. It also obviates the necessity of the complicated workaround called NAT, without which IPv4 is impractical these days.
It's more like the imperial vs metric system debate. If the world hadn't seen IPv4, I believe that we'd all be using IPv6 without any complaints. The real problem is that IPv6 isn't taught well.
> Separate from that, deliberate decisions were made to make it a "clean slate" without consideration for existing ipv4 hosts. Guess they were hoping the separate stacks would go away eventually, but in hindsight, no way.
I'm not sure what to make of this. The presence of the IPv4 stack isn't what blocks the adoption of IPv6 - at least not technically. They can coexist on the same host and function concurrently without interfering with each other. It was designed to operate like that. The actual blocker is the attitude that people hold towards IPv6 - "We have IPv4 that works already. Why should we care about an alternative?". You can see that expressed on this discussion thread itself.
There is one crucial detail that the IPv6 detractors neglect - the scarcity of IPv4 addresses means that IPv4 address blocks are now heavily coveted and therefore subject to moneyed interests. That isn't very good for the health of the open internet, digital rights and equity. They're thinking about individual trees and losing sight of the whole damn forest. IPv6 isn't a solution looking for a problem. It's the solution for a problem that people simply ignore.
NAT is technically complicated if you're looking inside it, but most people aren't, and for them it's really easier to think about. You've got a public and a private, and there's a very strong default that private isn't exposed. People screw up firewall rules all the time or routers have bad defaults, but it takes more deliberate action to publicly expose a port over NAT. Plus you don't need privacy addresses that way (introduced to ipv6 in 2007). I know "NAT isn't security" but for most people, it is.
Still not even sure what the accepted default firewall behavior is in ipv6, cause some people say "ipv6 lets any device do p2p by its own choice" and then when you ask about security, "your router firewall should always default-deny anyway," so which one is it?
> The presence of the IPv4 stack isn't what blocks the adoption of IPv6
It is. Like they say, most technical problems are really people problems, especially this one.
Many (most?) SOHO routers already run a combined DHCP and DNS server called 'dnsmasq', which supports DHCPv6. IIRC, dnsmasq automatically adds DNS records for hosts to which it gives out a lease. Android computers don't use DHCPv6, so this won't help you access them by name, but how often do you care to directly access an Android computer?
The fellow I replied to indicated that running a local DNS server on one's LAN "sounds crazy".
My commentary was intended to indicate that it's very common in SOHO networks to already be running a DNS server that automatically adds hostname->address mappings of DHCP clients on that network. It also mentioned that DHCPv6 support is supported by the combined DHCP+DNS daemon used by many (most?) SOHO routers.
My commentary was not intended to indicate that DHCPv6 support is on by default on many or most SOHO routers, only that it's likely to be supported, and that -if supported- it is very, very likely to put hostname->AAAA mappings of DHCPv6 clients into its DNS server, just as it adds hostname->A mappings for DHCPv4 clients.
If you're using a SOHO router, you're very likely to already be using dnsmasq; a DNS server. In that configuration, if you're using DHCP then you get your hostnames in DNS for free.
If you're not using DHCP and don't have a DNS server running on your network that you have figured out how to update with host IP addresses, then it's on you to select memorable static addresses. [0] This is a long-standing baseline fact of IP addressing for LANs and other private networks.
[0] Nothing prevents you from assigning addresses to your LAN machines in the fd00::/64 prefix starting from 1 (that is, fd00::1) and going up. The fd00::/8 space is for uncoordinated network-local addressing.
Programs will teach Docker only years after it is adopted.
Same with AWS, JavaScript, etc.
If it’s not adopted by industry, it won’t be taught about in schools.
To be clear, degree programs have value, but it’s not in future-proofing students against needing to learn things after they leave school. Ideally it should prepare them and encourage them to do so.
I am not doubting you, but I feel this story is too hard to believe without adding further nuances...
MIT 6.829 teaches IPv6 since 2002: https://ocw.mit.edu/courses/6-829-computer-networks-fall-200...
In Portugal and other countries, there are subjects on Computer Science before College or University, and they teach it on High School...
Then there is usually a chapter on IPv6 that just briefly covers the differences.
I.e. the exercises all tend to use IPv4 as the foundation so people don’t practice v6
IPv4 is, for all intents and purposes, still the default transport. It’s also simpler than IPv6 in some regards. When teaching layer 3, it makes sense to teach both, and teach IPv4 first. Though I fully agree that they should be taught with equal emphasis. I don’t doubt there’s a good number of programs out there that don’t into sufficient detail on IPv6.
IP addresses show up everywhere when you are working with both TCP and HTTP. Sockaddr is all over sockets programming, IPs show up in HTTP headers, etc.
They absolutely care about the underlying protocol because the underlying protocol is how you address the other end.
People complain about dual stacks and all that but with a modicum of planning it is minimal extra effort. Anything made in the last decade has V4/V6 support and unless you're messing with low level network code, it's often difficult to even know which way you're being routed. Network devices pretty much all support using groups of names or addresses and not hard coded dotted-quad config statements now, and have for a while. And that was good practice on V4 networks too.
Part of it is probably that remembering various V4 magic is easy enough to do but feels complicated enough to be an accomplishment. In V6, there is no point in doing most of that because the protocol has so much more automation of addressing schemes. But if you like those addressing schemes, V6 can do them even better. You can do all sorts of crazy address translation on either the network or host id portion, like giving an internal network a ULA that is magically translated to a public network prefix without any stateful tracking unless that is desirable.
I feel there is some analog to DNS in that regard, people who have gotten used to DNS don't give a damn about host IP addresses but some people seem to really like the idea of a fixed address statement. People also seem to be stuck on the idea that NAT creates some kind of security when that's really the stateful tracking that is required for many-to-few translations (thus making firewalls a common place to implement it), not the translation itself. Similar to certificates/pki versus shared keys, yes, one is more upfront effort but that's because it's solving the problem of the Sisyphean task that is the other.
edit: This all reminded me that we lived with dual stacks before, in the IP and IPX days, or DECnet, and that GE Ether-whatever, and those had less in common. IPX mostly died with Netware but it had a number of advantages that wouldn't be bolted on top of IP for years, some of which are present in IPv6. I rather liked IPX and had history gone differently that it used 48-bit addressing would be causing us to discuss whether or not EUID was a mistake or not :)
A successor to ipv4 wasnt a technical issue. duh, use longer addresses. The problem was social.
It's a miracle it was used at all
What's annoying about ipv6 discussions is that the ipv6 people are incredibly condescending when the problems of its adoption were engineered by them.
But the social/political environment was that everyone just wants to be a passive consumer, paying monthly fees to centralized hosts to spoon-feed them content through an algorithm. For that, everyone being stuck behind IPv4 CG-NAT and not being able to host anything without being gatekept by the cloud providers is actually a feature and not a bug.
Cloudless cameras streaming to your phone without Chinese vendor clouds, e2e encrypted emails running on your phone without snooping by marketing people and three-leter agencies, content distribution network without vendor lock-ins. The possibilities are impressive if we have a way to do it without TURN servers that cost money and create a technical and legal bottlenecks.
We can't say nobody wants that world because we've never tried it in the first place. I definitely would like to see that.
I was lucky enough to experience the 90's internet where static IP addresses were common. I had a /24 (legacy "class C" block) routed to my home, and still do.
IPv6 was developed in the open on mailing lists that anyone could subscribe to:
The criteria presented here were culled from several sources,
including "IP Version 7" [1], "IESG Deliberations on Routing and
Addressing" [2], "Towards the Future Internet Architecture" [3], the
IPng Requirements BOF held at the Washington D.C. IETF Meeting in
December of 1992, the IPng Working Group meeting at the Seattle IETF
meeting in March 1994, the discussions held on the Big-Internet
mailing list (big-internet-at-munnari.oz.au, send requests to join to
big-internet-request-at-munnari.oz.au), discussions with the IPng Area
Directors and Directorate, and the mailing lists devoted to the
individual IPng efforts.
Just like all current IETF discussions are in the open and free for all to participate. If you don't like the direction things are going in participate: as Gandhi did (not) say, “Be the change you want to see in the world.”
One of the co-authors on that RFC worked at BBN: you know, the folks that actually built the first the routers (IMPs) that created the ARPA/Internet in the first place. I would hazard to guess they have know something about network operations.
* https://www.goodreads.com/book/show/281818.Where_Wizards_Sta...
> But the social/political environment was that everyone just wants to be a passive consumer, paying monthly fees to centralized hosts to spoon-feed them content through an algorithm.
Disagree, especially with the hoops that users and developers have to jump through to deal with (CG-)NAT:
> [Residential customers] don't care about engineering, but they sure do create support tickets about broken P2P applications, such as Xbox/PS gaming applications, broken VoIP in gaming lobbies, failure of SIP client to punch through etc. All these problems don't exist on native routed (and static) IPv6.
* https://blog.ipspace.net/2025/03/response-end-to-end-connect...
The real reason is IT people hate ipv6. They want NAT. They don't want all the security holes and extra complexity. I don't want having to work with a network stack that is poorly supported by some switches and routers.
Replace "IPv6" in that sentence with any practical knowledge or skill and it's probably true for my entire master's degree....
--Sent from my IPv6
I agree it will not die so I retract that statement, but it will never fully replace IPv4 in standard wired internet connections.
My ISP has finally mastered providing me with reliable albeit slow DSL. Fiber would change my life, there just isn't any point in asking for IPv6.
Also note those bloated packets are death for many modern applications like VoIP.
I went from being pumped to learn more to realizing I’m going to invest a lot of time and I could not identify and tangible benefit.
(The flip side is having a network-level firewall is more important than ever.)
You also don't have to worry about running a DHCP server anymore, at least on small networks. The simplicity of SLAAC is a breath of fresh air, and removes DHCP as a single point of failure for a network.
I'll take full security by default and forward a couple of ports thankyou!
Loopback, link local and network assigned. What's that problem? Your ipv4 hosts are can reach themselves through millions of addresses already.
> hostnames are replaced by auto assigned stuff from the ISP
Hostnames replaced? IPv6 doesn't do DNS...
> lots of random things don’t work.
Lots of random things also don't work on ipv4. :)
For example, two IPv6 peers can often trivially reach each other even behind firewalls (using UDP hole punching). For NAT, having too restrictive a NAT gateway on either side can easily prevent reachability.
Huh? The packet sizes aren’t that much different and VOIP is hardly a taxing application at this point anyway. VOIP needs barely over dial-up level bandwidth.
https://www.nojitter.com/telecommunication-technology/ipv6-i...
Edit: NAT also adds measurable latency. If anything I’d think avoiding NAT might actually make IPv6 lower latency than IPv4 on average.
I think it would have been better having shorter addresses and not waste so many on every endpoint.
With a fixed size host identifier compared to a variable size ipv4 host identifier network renumbering becomes easier. If you separate out the host part of the ip address a network operator can change ip ranges by simply replacing the top 64 bits with prefix translation and other computers can still be routed to with the unique bottom 64 bits in the new ip network.
This is what you do if you start with a clean sheet and design a protocol where you don't need to put address scarcity as the first priority.
Aside, isn't embedding MAC addrs in ones IP address a bad idea?
You will sometimes see admins complain that IPv6 demands that you allow ICMP (at least the TOOBIG messages) through the firewall because they're worried that people on the internet will start doing pingscans of their network. This is because they do not understand what 2^64 is.
Hint: the ICMPv6 packet is no shorter than 48 bytes and there are 1.8446744e+19 addresses to scan.
To be fair, the "big" cloud providers can't seem to figure this shit out, either. It's mind boggling, I'm not saying I've gone through the headache of banging out all the configuration to get FRRouting and my RouterOS gear happily doing the EVPN-VXLAN dance; but I'm also not Amazon, Google, or Microsoft...
But when designers bring things like that up, you get “it’s really not that complicated,” or “I explained this to my 200 year old grandmother over tea/my 16 month old child over the course of a diaper change/my non-technical wife that I intellectually respect less than I should/etc. and they wrote a book on it the next day,” kind of crap. Human factors engineering. Ergonomics matter in technical products.
In particular, just off the top of my head...
- T-Mobile US doesn't even assign clients an IPv4 address anymore. Their entire network is IPv6 native.
- Many cloud providers charge extra for IPv4 addresses, but give IPv6 addresses out for free.
Personal anecdote, but once you have IPv6 setup properly (meaning your devices prefer IPv6 over IPv4) 70-80% of your internet traffic will be IPv6.
The NAT64 is really just there for the holdouts.
I'm sure that DC customers used their Edison DC equipment for decades after the grid went AC only; but in the long run the newer, flexible, lower overhead system became the default for new equipment and the compatibility cludges were abandoned.
This is not really true of IPv6. It _still_ has tons of actual operational issues, and in the best case, it does not provide any tangible improvements over IPv4+NAT for the vast majority of users.
For example, in-flight entertainment works by assigning you an IPv4 address and allowlisting it in the gateway rules. This does not work with IPv6 because of privacy addresses and SLAAC. You might think that you just need to do stateful DHCPv6, but Android doesn't support it. Heck, even simple DHCPv6 PD automatic configuration is _still_ not a standard ( https://datatracker.ietf.org/doc/rfc9762/ )!
So to this day, some of the most visited sites like amazon.com, ebay.com, tiktok.com, slack.com or even github.com do not support IPv6. I also keep providing this example, year after year: there are no public VoIP SIP providers in the US that simply _support_ IPv6. Go on, try to find one.
Isn’t it what all the cell phones networks use these days? And most ISP’s?
They may hand the end user device a IPv4 address but don’t they actually use IPv6?
IPv6 only ISPs will never leave the mobile space.
I would say its more "Wireless only ISPs are the only ones using it"
So… the largest ISPs.
Recent number show about 94% of Americans have cell phones and 92% of American households have Internet connections. In raw numbers, that’s about 300M cell phones and 111M households.
If zero fixed ISPs support IPv6, that’d still be about 75% of total Internet connections that do.
Yep, a few gatekeepers of a single device space.
Your numbers are wrong, seee the google graph everybody is pointing to:
- You have to pay money to get a static IPv4 address for cloud machines on eg AWS. Anything needing a static IPv4 will cost more and more as demand increases. NAT doesn’t exactly fix that.
- Mainstream IoT protocols have a hard dependency on IPv6 (eg Matter/Thread). Not to mention plenty of 5g deployments.
- Many modern networks quietly use IPv6 internally. I mean routing is simpler without NAT.
So it almost definitely won’t die. It’s more likely it’ll slowly and quietly continue growing behind the scenes, even if consumers are still seeing IPv4 on their home networks.
More IPv6 deployments may (ironically?) help reduce IPv4 prices as you can get IPv6 'for free' and have Internet connectivity (and not have to worry about exhaustion in any practical way). Doing CG-NAT could reduce the number IPv4 addresses you need to acquire.
This graph is mainly due to the fact that telcos use IPv6 for mobile devices, nothing more. Over time you will see that graph flatline and peter out as mobile device uage reaches critical mass.
afaik every single major US fixed line ISP is rolling out ipv6.
Show me one where they have disabled IPv4 and only use IPv6 that is not a mobile device or Telco ISP.
Hell, chances are if you got a new router (like any new client) for your ISP, you’d be on v6 too.
Pretty much all ISPs hand out both IPv6 and IPv4 addresses to their clients, this is nothing new. When they start only issueing IPv6 IPs is when it would start truly taking off, but it will never get to that point and it will never happen.
However In another thread it was argued that when IPv4 addresses become very expensive, that could trigger a big shift to IPv6. I agree with this statement and so IMO it is possible that IPv6 may well become ubiquitous in the future.
IPv4 is the one that descriptor belongs on, eh?
Usage is in no way 'rapidly increasing', in fact the google graph everyone is touting around shows that it has taken over 10 years to not even get to 50%. It also shows it is slowing down, the curve is starting to become less steep.
When Maximum possible IPv6 usage is not even at 50% after over a decade and the usage curve is slowing, how can you possibly say that IPv4 is dying and IPv6 usage is rapidly increasing?
So what, another decade and we should be mostly done?
What do you think is a reasonable amount of time to redo the entire world’s networking infrastructure across 200+ countries and 8 something billion people, exactly?
This is an absurd argument, you know that right?
No, but taking over a decade to not even be half adopted does not count as rapid in my opinion.
> So what, another decade and we should be mostly done?
No, as I have said many many times, the graph is slowing.
> What do you think is a reasonable amount of time to redo the entire world’s networking infrastructure
We dont need to, thats the point. All networking equipment in the world already supports IPv6, so why isnt it at 100% usage and IPv4 is turned off already?
>This is an absurd argument, you know that right?
Who is the fool, the person saying what they think or the person continuing to participate in an argument they consider absurd?
You dont need to make everybody in the world agree with what you are saying, it is ok to have differing opinions. You know that right?
I am done now. I accept that you disagree with me and thats fine. Can you afford the same decency or will you continue to tell me I'm wrong?
Those are the only two countries that could plausibly have billions of mobile devices and they appear to have reached 50%.
India: https://stats.labs.apnic.net/ipv6/CN?c=IN&x=1&v=1&p=1&r=1&w=...
China: https://stats.labs.apnic.net/ipv6/CN?c=CN&x=1&v=1&p=1&r=1&w=...
I have an opinion on something, I assume thats ok? You seem to be here trying to prove me wrong, and also commenting on my tone of reply.
Im not trying to tell you that you are wrong, only stating what I think. If you dont like my opinion, feel free to ignore it. You are not forced to comment.
[https://www.google.com/intl/en/ipv6/statistics.html]
What exactly are you going on about? 5-10 years for the old devices to be EOL’d, and we’ll likely be at 95%.
There is no chance we will be at 95% usage in 5 years or so.
If you like, we can make a wager?
As it is, that graph is showing how adoption is slowing and has been for the last 10 years.
Hardly anybodies physical internet connection is using IPv6 primarily worldwide, those numbers are all mobile device space.
...what? The majority of people access the Internet from their phone, and not only since yesterday either. Are you arguing that this is temporary fad somehow?
I personally believe that at about 60% utilisation the line on the graph will become flat and stay that way.
You can look at the AS breakdowns on APNIC's stats and see that ASs that serve non-mobile customers are getting v6, and that some ASs for mobile users aren't. So no, it won't stall.
Slow down perhaps, but it has to slow down at some point or it'll go above 100%.
I'll get endless pushback for this, but the reality is that adoption isn't at 100%, it very closely needs to be, and there are still entire ISPs that only assign ipv4, to say nothing of routers people are buying and installing that don't have ipv6 enabled out of the box.
A much better solution here would have been an incredibly conservative "written on a napkin" change to ipv4 to expand the number of available address space. It still would have been difficult to adopt, but it would have the benefit of being a simple change to a system everyone already understands and on top of a stack that largely already exists.
I'm not proposing to abandon ipv6, but at this point I'm really not sure how we proceed here. The status quo is maintaining two separate competing protocols forever, which was not the ultimate intention.
"And what do you base this belief on?
Fact is you'd run into exactly the same problems as with IPv6. Sure, network-enabled software might be easier to rewrite to support 40-bit IPv4+, but any hardware-accelerated products (routers, switches, network cards, etc.) would still need replacement (just as with IPv6), and you'd still need everyone to be assigned unique IPv4+ addresses in order to communicate with each other (just as with IPv6)."[0]
If you treat IPv4 addresses as a routable prefix (same as today), then the internet core routers don't change at all.
Only the edge equipment would need to be IPv4+ aware. And even that awareness could be quite gradual, since you would have NAT to fall back on when receiving an IPv4 classic packet at the network. It can even be customer deployed. Add an IPv4+ box on the network, assign it the DMZ address, and have it hand out public IPV4+ addresses and NAT them to the local IPv4 private subnet.
IPv6 seems to be a standard that suffered from re-design by committee. Lots of good ideas were incorporated, but it resulted in a stack that had only complicated backwards compatibility. It has taken the scale of mobile carriers to finally make IPv6 more appealing in some cases than IPv4+NAT, but I think we are still a long way from any ISP being able to disable IPv4 support.
"Only"? That's still the networking stack of every desktop, laptop, phone, printer, room presentation device, IoT thing-y. Also every firewall device. Then recompile every application to use the new data structures with more bits for addresses.
And let's not forget you have to update all the DNS code because A records are hardcoded to 32-bits, so you need a new record type, and a mechanism to deal with getting both long and short addresses in the reply (e.g., Happy Eyeballs). Then how do you deal with a service that only has a "IPv4+" address but application code that is only IPv4-plain?
Basically all the code and infrastructure that needed to be updated and deployed for IPv6 would have to be done for IPv4+.
How could it have been otherwise given the original network structures were all of fixed lengths of 32 bits?
What we needed was the equivalent of ASCII->UTF8.
As I see it, the transition mechanism for some IPv4+ that 'only' has longer addresses is exactly the same as for IPv6: new code paths that use new data structures, with a gradual rollout with tech refreshes and code updates where hosts slowly go from IPv4-only to IPv4-and-IPv4+ at different rates in different organizations.
If you think it's somehow different, can you explain how it is so? What proposal available (especially when IPng was being decided on in the 1990s) would have allowed for a transition that is different than the one described above (gradual, uncoördinated rollout)?
DNS is like today: A and AAAA records for IPv4 and IPv4+ respectively.
Core routers do not need to know about IPv4+, and might never know.
The transition is similar to 6to4. The edge router does translation to allow IPv4+ hosts to connect to IPv4 hosts. IPv4 hosts are unable to connect to IPv4+ directly (only via NAT). So it has the similar problem to IPv6 that you ideally want all servers to have a full IPv4 address.
What you don't have is a completely parallel addressing system, requirements to upgrade all routers (only edge routers for 4+ networks), requirements to have your ISP cooperate (they can just give you an IPv4 and you handle IPv4+ with your own router), and no need that the clients have two stacks operating at once.
It's essentially a better NAT, one where the clients behind other NATs can directly connect, and where the NAT gradually disappears completely.
shrug
Most of the world is a circus.
In networking terms, this is like a protocol which can reach ipv4 hosts only but loses packets to the ipv4+ hosts randomly depending on what it passes through. Who would adopt a networking technology that fails randomly?
We've never done something like the v4->v6 migration before, on this sort of scale. It's not clear what the par time for something like this is. Maybe 30 years is a normal amount of time for it to take?
3 billion people sorta use ipv6, but not really, cause almost all of those also rely on ipv4 and no host can really go ipv6-only. Meanwhile, many sites are HTTPS-only.
Layer 3 of the Internet is the one that requires support in all software and on all routers in the network path, and those are run by millions of people in hundreds of countries with no central entity that can force them to do anything.
HTTP->HTTPS is only similar in terms of number of users, not in terms of the deployment itself. The network effects for IP are much stronger than for HTTP.
They don't "sorta" use v6, they're properly using it, and you can certainly go v6-only. I'm posting from a machine with no v4. Also, if you want to go there: HTTPS was released before IPv6, and yet still no browser is HTTPS only, despite how much easier it is to deploy it.
Most browsers now discourage plain HTTP with a warning. Any customer-facing server basically needs to use HTTPS now. And you're rare if you actually have no ipv4, not even via a tunnel.
If they only got one shot at changing HTTP, do you think they would have tied TLS to HTTP/2 or given up on HTTP/2 altogether?
I don't know if HTTP's job is easier. Maybe on the client side, since there were never that many browsers, but you have load-balancers, CDNs, servers, etc. HTTP/2 adoption is still dragging out because of how many random things don't support it. Might be a big reason why gRPC isn't so popular too.
HTTP->HTTPS is not equivalent in any way. The payload in HTTP and HTTPS are exactly the same; HTTPS simply adds a wrapper (e.g., stunnel can be used with an HTTP-only web server). Further HTTP(S) is only on the end points, and specifically in the application layer: your OS, switch, firewall, CPE, ISP router(s), etc, all can be left alone.
If you're not running a web browser or web server (i.e., FTP, SMTP, DNS, database) then there are zero changes that need to be made to any code on a system. This is not true for changing the number of bits the addressing space: every piece of code that calls socket(), bind(), connect(), etc, has to be touched.
Whereas the primary purpose of IPng was to expand the address space, which means your OS, switch, firewall, CPE, ISP router(s), etc, all have to be modified to handle more address bits in the Layer 3 protocol data unit.
Plus stuff at the application layer like DNS (since A records are 32-bit only, you need an entire new network type): entire new library functions had to be created (e.g., gethostbyname() replaced by getaddrinfo()).
I hear people say the IETF/IP Wizards of the 1990s should have "just" picked an IPng that was a larger address space, but don't explain how IPv4 and hypothetical IPv4+ would actually work. Instead of 1.1.1.1, a packet comes in with 1.1.1.1.1.1.1.1: how would a non-IPv4+ router know what to do with that? How would non-updated routers and firewalls be able to handle longer addresses? How would non-updated DNS code be able to handle new record types with >32 bits?
To answer the last question, routers would need IPv4+ support, just like ipv6 which already happened. The key is it's much easier for users to switch after. No dual stack, you get the same address, routes, DNS, and middleboxes like NAT initially. ISPs can't hand out longer addrs like /40 until things like DNS are upgraded in-place to support that, but again those are pretty invisible changes throughout the stack.
So exactly like IPv6: you need to roll out new code everywhere.
> The key is it's much easier for users to switch after. No dual stack, you get the same address, routes, DNS, and middleboxes like NAT initially. ISPs can't hand out longer addrs like /40 until things like DNS are upgraded in-place to support that, but again those are pretty invisible changes throughout the stack.
So exactly like IPv6: you need to roll out new code everywhere.
Would organization have rolled out in IPv4+ any differently than IPv6? Some early, some later, some questioning the need at all. It's the exact same coördination / herding cats problem.
* roll out new code everywhere
* enable the protocol on your routers
* get address block(s) assigned to you
* put those blocks into BGP
* enable the protocol on middleware boxes
* have translation boxes for new-protocol hosts talk to old-protocol-only hosts
* enable the protocol on end hosts
And just because you do it, does not mean anyone else would do in the same timeframe (or ever). You're back in the chicken-and-egg of whether servers/services do it first ("where are the clients?"), or end-devices ("where are the services?").
Application rework would be exactly the same as with v6, because the issue was not with v6 but with BSD Sockets API exposing low-level details to userland.
Congratulations, you’ve re-invented CGNAT, with none of the benefits, and the additional hassle of it being an entirely new protocol!
No. No “extra bits” on an IPv4 address would have ever worked. NAT itself is a bug. Suggesting that as an intentional design is disingenuous.
The edge router has an IPv4+ subnet (either a classic v4 address, or part of a v4+ address). It maintains an L2 routing table with ARP+, and routes IPv4+ packets to the endpoint without translation. Private subnetting and NAT is only needed to support legacy IPv4 clients.
CGNAT pools IPv4 public addresses and has an expanded key for each connection, and translates either 4 to 6 or into a private IPv4 subnet. My proposal needs no pooling and only requires translation if the remote host is IPv4 classic and the edge router is not assigned a full IPv4+/24.
And since the goal is “backwards-compatability”, you’d always need to poll, because a “legacy” IPv4 client would also be unable to send packets to the IPv4+ destination. Or receive packets with an IPv4+ source address.
And it would be an absolute nightmare to maintain. CGNAT + a quasi backwards-compatible protocol where the backwards-compatability wouldn’t work in practice.
So you would have exactly the same problem as IPv6. I can say the same about v4 and v6 today. You could just turn off IPv4 on the internet, and we’d only need to do translation on the edge for the legacy clients that would still use IPv4. You can even put IPv4 addresses in IPv6 packets!
Each v4 address has a corresponding /48 of IPv6 tunnelled to it. The router with that IP receives the tunnelled v6 packets, extracts them and routes them on natively to the end host. This is something that v6 already does, so you don't need to make posts complaining about how dumb they were for not doing it.
It's an edge based solution similar to NAT, but directly addressable. And given that it extends IPv4, I think it would have been much more "marketable" than IPv6 was.
But again, this is all counterfactual. The IETF standardized IPv6, and 30 years on it's still unclear that we will deprecate IPv4 anytime soon.
I base it on comparing how the IPv2 to IPv4 rollout went, versus the IPv4 to IPv6 rollout. The fact that it was incredibly obvious how to route IPv2 over IPv4 made it a no-brainer for the core Internet to be upgraded to IPv4.
By contrast it took over a decade for IPv6 folks to accept that IPv6 was never going to rule the world unless you can route IPv4 over it. Then we got DS-Lite. Which, because IPv6 wasn't designed to do that, adds a tremendous amount of complexity.
Will we eventually get to an IPv6 only future? We have to. There is no alternative. But the route is going to be far more painful than it would have been if backwards compatibility was part of the original design.
Of course the flip side is that some day we don't need IPv4 backwards compatibility. But that's still decades from now. How many on the original IPv6 will even still be alive to see it?
Or what do you mean by “parts of an IPv4 address and their meaning”?
That multicast on IPv4 isn’t used as much is irrelevant. It functions the same way in both protocols.
And then all the defaults about how basically everything works are different. Home router in v6 mode means no DHCP, no NAT, and hopefully yes firewall. In theory you can make it work a lot like v4, but by default it's not.
In my experience the differences are just an excuse, and however similar you made the protocol to IPv4 the people who wanted an excuse would still manage to find one. Deploying IPv6 is really not hard, you just have to actually try.
I think they also wanted to kill NAT and DHCP everywhere, so there's SLAAC by default. But turns out NAT is rather user-friendly in many cases! They even had to bolt on that v6 privacy extension.
With ipv6, that can be simplified with just a couple of /32 or /48 prefixes per AS.
How is IPv6 "so different" than IPv4 when looking at Layer 3 and above?
(Certainly ARP vs ND is different.)
In what way? Longer addresses? In what way is it "so different" that people are unable to handle whatever differences you are referring to?
We used to have IPv4, NetBEUI, AppleTalk, IPX all in regular use in the past: and that's just on Ethernet (of various flavours), never mind different Layer 2s. Have network folks become so dim over the last few years that they can't handle a different protocol now?
“most what they know from IPv6” is just NAT.
> A less ambitious IPv4 is exactly what we need in order to make any progress
but we’re already making very good progress with IPv6? Global traffic to Google is >50% IPv6 already.
Therefore if I'm on an IPv6 phone, odds are very good that my traffic winds up going over IPv4 internet at some point.
We're 30 years into the transition. We are still decades away from it being viable for servers to run IPv6 first. You pretty much have to do IPv4 on a server. IPv6 is an afterthought.
Just put Cloudflare in front of it. You don’t need to use IPv4 on servers AT ALL. Only on the edge. You can easily run IPv6-only internally. It’s definitely not an afterthought for any new deployments. In fact there’s even a US gov’t mandate to go IPv6-first.
It’s the eyeballs that need IPv4. It’s a complete non-issue for servers.
Why do I have to get some third party involved??
Listen, you can be assured that the geek in me wants to master IPv6 and run it on my home network and feel clever because I figured it out, but there's another side of me that wants my networking stuff to just work!
NAT is RFC 1631.
IPv6 is RFC 1883.
Admitted, that was very basic NAT.
Actually, my bad. NAT was NEVER standardized. Not only NAT was never standardized, it’s never even been on standards track. RFC 3022 is also just “Informational”
Plus, RFC 1918 doesn’t even mention NAT
So yes, NAT is a bug in history that has no right to exist. The people who invented it clearly never stopped to think on whether they should, so here we are 30 years later.
The protocols involving NAT are what end up on the standards track like FTP extensions for NAT (RFC 2428), STUN (RFC 3489), etc.
201.20.188.24.6
And most of what they know about how it works clicks in their mind. It just has an extra octet.
I also think hardware would have been upgraded faster.
Something like aaff:a.b.c.d
Leaving off the prefix: could just mean strictly IPv4.
It didn’t speed up adoption and people then tried most of the other solutions people are going to suggest for IPv4+. Want the IPv4 address as the network address instead? That’s 2002:a.b.c.d/48 - many ISPs didn’t deploy that either
For people who deal with ip addresses, the switch from ipv4 to ipv6 means moving from 4 digits (1.2.3.4) to this:
2001:0db8:0000:0000:0008:0800:200c:417a
2001:db8:0:0:8:800:200c:417a
2001:db8::8:800:200c:417a
Plus switching completely to ipv6 overnight means throwing away all your current knowledge of how to secure your home network. For lazy people, ipv4 NAT "accidentally" provides firewall-like features because none of your home ipv4 addresses are public. People are immediately afraid of ipv6 in the home and now they need to know about firewalls. With ipv4, firewalls were simple enough. "My network starts with 192.168, the Internet doesn't". You need to learn unlearn NAT and port forwarding and realise that with already routable ipv6 addresses you just need a firewall with default deny, and then add rules that "unlock" traffic on specific ports to specific addresses. Of course more complexity gets in the way... devices use "Privacy Extensions" and change their addresses, so making firewall rules work long-term, you should use the device's MAC Address. Christ on a bike.
I totally see why people open this bag of crazy shit and say to themselves "maybe next time I buy a new router I'll do this, but right now I have a home with 4 phones, 3 TVs, 2 consoles, security cameras, and some god damn kitchen appliances that want to talk to home connect or something". Personally, I try to avoid fucking with the network as much as possible to avoid the wrath of my wife (her voice "Why are you breaking shit for ideological reasons? What was broken? What new amazing thing can I do after this?").
Try `ping 16909060` some day :-)
v6 has optional leading zeros and ":: splits the address in two where it appears". v4 has field merging, three different number bases, and it has optional leading zeros too but they turn the field into octal!
LOL. Yup. What can I do after this? The answer is basically "nothing really" or "maybe go find some other internet connection that also has IPv6 and directly connect to one of my computers inside the network (which would have been firewalled I'd hope so I'd, what, have to punch open a hole in the firewall so my random internet connection's IPv6 can have access to the box? how does that work? I could have just VPN'd in with the IPv4 world).
Seriously though, how do I "cherry pick hole punch" random hotel internet connections? It's moot anyway because no hotel on earth is dishing out publicly accessable IPv6 addresses to guests....
Just like for an apartment you append something like 5B. And for a house you don't need that.
I don’t even buy your way of thinking - unlike an “engineering” solution or an “incentives” solution, the problem with “social solutions I speculate about” is: they offer nothing until implemented. They are literally all the same, no difference between the whole world of social solutions, until they are adopted. They are meaningless. They’re the opposite of plans.
Like what’s the difference between IPv4+, which doesn’t exist, and “lets pass a law that mandates ipv6 support”? Nothing. This is what the mockery of “just pass a law” is about. I don’t like those guys, but they are right: it’s meaningless.
It couldn't do that reliably. We don't have any flags left for that that. Options are not safe. We've got one reserved flag which is anyways set to 0, so that's not safe either.
There's the reserved bit (aka the evil bit[1]). Are you saying gear out there drops packets with reserved bit set to 1? Wouldn't surprise me, just curious.
Seems like IPv4+ would have been a good time to use that bit. Any IPv4+ packets could have more flags in the + portion of the header, if needed.
For ping, I think it originally had different binaries because ICMPv4 and ICMPv6 are different protocols, but Linux has had a dual-stack `ping` binary for a very long time now. You can just use `ping` for either address family.
The ISPs aren't gonna do it on their own.
But IPv4 will never, ever die. The rise of NAT as a pervasive security paradigm[1] basically neuters the one true advantage IPv6 brought to the table by hiding every client environment behind a single address, and the rise of "cloud everything" means that no one cares enough about reaching peer devices anyway. Just this morning my son asked me to share a playlist, so of course I just send him a link to a YouTube Music URL. Want to work on a spreadsheet for family finances with your spouse in the next room? It lives in a datacenter in The Dalles.
[1] And yes, we absolutely rely as a collective society on all our local devices being hidden. Yes, I understand how it works, and how firewalls could do this with globally writable addresses too, yada yada. But in practice NAT is best. It just is.
Honestly it's a huge success due to this fact alone.
IPv6 is failure only if you measure success by replacing IPv4 or if you called "time" on it before the big mobile providers rolled it out. The fact that all mobile phones support it and many mobile networks exclusively deploy it tells you what you really need to know.
IPv6 is a backbone of the modern Internet for clients, even if your servers don't have to care about it due to nat64.
Ultimately, an address system that replaces “1.1.1.1” with “JEDBSO:7372B6D6A:727:8:72829:762927” or whatever just isn’t viable.
Even AWS doesn’t let you use IPv6 with anything… and they charge you for using IPv4 now.
Shocking it took them so long but, hey, it's there now.
I can tell you what is what simply from the Ipv4 address, but when its IPv6, my dyslexia is going to kick my behind.
Readability reduces errors, and IPv6 is extreme unreadable. And we have not talked yet about pre-fix, post-fix, that range :: indicator, ... Reading a Ipv6 network stack is just head pain inducing, where as Ipv4 is not always fun but way more readable.
They where able to just extend IPv4 with a extra range, like 1.192.120.121.122, 2.... and you have another 255 Ipv's ... They did the same thing for the Belgium number plates (1-abc-001) and they will run out in the year 11990 somewhere lol...
The problem is, that Ipv6 is over engineered, and had no proper transition from Ipv4 > Ipv6 build in, and that is why 30 years later, we are still dealing with the fallout.
Of course that’s due to the relatively small amount of information it contains and having a larger address space is always going to break that.
I think the same thing happens on a different scale with ISPs. They don't want to deal with it until they have to for largely the same reason.
In my experience it’s much easier and much more pleasant do deal with. Every VLAN is a /64 exactly. Subnetting? Just increment on a nibble boundary. Every character can be split 16 ways. It’s trivial.
You don’t even need to use a subnet calculator for v6, because you can literally do that in your head.
Network of 2a06:a003:1234:5678::555a:bcd7/64? Easy - the first 4 octets.
Network of 10.254.158.58/27? Your cheapest shotgun and one shell please.
"Easy,2a06:a003:1234:5678"
"2806:8003: and then what, I forgot the rest?"
remembering 2a06:a003:1234:5678::555a:bcd7/64. Your cheapest shotgun and one shell please.
e.g. you’ll get 2a06:a003:1234::/48 from the ISP - what you’ll really need to remember is the 2a06:a003:1234:xxxx::/64 part. And I use the VLAN id for the xxxx part. Trivial.
I DO think using 64 bits for hosts was stupid but oh well.
Why have so, so many address bits and then give us so few for subnetting? People shame ISPs endlessly for only giving out /56s instead of /48s, pointing at the RFCs and such. But we still have 64 entire bits left over there on the right! For what? SLAAC? Was DHCP being stateful really such a huge problem that it deserves sacrificing half of our address bits?
We're past that for a decade, but various services have not caught up yet https://datatracker.ietf.org/doc/html/rfc6177
The actual intention has always been that there be no hard-
coded boundaries within addresses, and that Classless Inter-
Domain Routing (CIDR) continues to apply to all bits of the
routing prefixes.Hey man, if I want to assign an address for each individual transistor in my system, that's my business.
I'm not sure what that feature would be though.
Networking should be boring.
Small site multihoming, for example, is an absolute disaster. Good luck if you're trying to add a cellular backup to your residential DSL connection.
IETF says you should either have multiple routers advertising multiple provider-assigned prefixes (a manageability nightmare), or that you should run BGP with provider independent address space; have fun getting your residential ISP or cellular carrier onboard with this idea.
They're not building products, and they're not supporting, visiting or even talking to their customers. Design-by-committee is a full time job that people actually building things for a living tend to not have time for.
The fact is that already in 1993 routing tables were just too big, and the fact is that having a "flat" address space was always going to mean huge routing tables, and the fact is that because IPv6 is still "flat" routing tables only got larger.
The fix would have been to have a subset of the address space that is routed as usual for bootstrapping ex-router address->AS number mapping, and then do all other routing on the basis of AS numbers _only_. This would have allowed us to move prefix->AS number mappings into.. well, DNS or something like it (DNS sucks for prefix mapping, but it could have been extended to not suck for prefix mapping), and all routing would be done based on AS numbers, making routing tables in routers _very small_ by comparison to now. Border routers could then have had tiny amounts of RAM and worked just fine. The IP packets could have borne AS numbers in addition to IP addresses, and all the routers in the middle would use only the AS numbers, and all the routers at the destination AS would know the routes to the destination IPs.
But, no. Great missed chance.
Well, we still could do this with IPv6, but it would be a lot of heavy lifting now.
EDIT: Ah, I see draft-savola-multi6-asn-pi existed.
EDIT: Ah, see also LISP [https://www.rfc-editor.org/rfc/rfc6830]. But LISP is essentially dead.
Hmm, what's the problem? I suppose your home devices should never be exposed to the public internet, and should only be accessible via a VPN like Wireguard. NAT64 is a thing if your home network is IPv4.
BTW what's the trouble with multi-homing? Can't an interface have two separate IPv6 addresses configured on it, the same way as IPv4 addresses?
Yes, an interface can hsve two separate IPv6 addresses, but that doesn't make it easy.
If you do the easy and obvious thing of setting up two routers to advertise their prefix with your preferred priority when they're available (and advertise it as unavailable when they're not), your devices are likely to configure themselves for addresses on both prefixes, which is great.
Then when you open a new tcp connection (for example), they'll pick a source address more or less randomly... There's a RFC suggestion to select the source address with the largest matching prefix with the destination address, which is useful if the prefix is pretty long, but not so useful when the prefix is 2001:: vs 2602::
Anyway, once the source address is selected, the machine will send the packet to whichever router most recently sent an announcement. Priorities only count among prefixes in the same announcement. If you manage to get a connection established, future packets will use the same source address, but will be sent as appropriate for the most recently received advertisement.
This is pretty much useless, if you want it to work well, you're better off with NAT66 and a smart NAT box.
I would experiment with advertising two default routes, one with a significantly higher metric than the other. Most / all outgoing traffic would go through one link then. If you want to optimally load both uplinks, you likely need a more intelligent (reverse) load balancer.
That's the problem. It sounds like it would work if you do this. The documentation suggests multi homing like this would work. When your server gets a request, it sends back the response from the address it received on... but the problem is what router it sends to; when it sends to the correct router, everything is good, when it sends to the wrong router, that router's ISP should drop the packets, because they come from a prefix they don't know about.
> I would experiment with advertising two default routes, one with a significantly higher metric than the other.
Sounds like it would work, but as far as I've found, the priority metric only works if the prefixes are in the same advertisement. If each router advertises its own prefix, the actual metric used is most recent advertisement wins as default route.
Because it breaks your network when that router goes away. Your switch ACLs, firewall rules, and DNS records all become invalid because they contain addresses that no longer exist, that your devices continue trying to reach anyway.
So every time I got a new prefix, machines would lose connectivity, usually until I rebooted them.
Switched to OpenWRT which respected my ULA.
But with multi-homing you would need to actively test which of your uplinks has Internet access anyway, won't you? And you would have to react somehow when one of your uplinks goes down.
It's easiest to do by abstracting your site away. Make it use a LAN, and do port-forwarding and proxying through a box that knows about the multiple uplinks, and handles the switch-over when one of them goes down. I don't see how it might be easier with IPv4 than with IPv6.
I still assume that you don't want the internals of your office network directly accessible via the public Internet, even when you easily can; VPNs exist for a reason.
> It's easiest to do by abstracting your site away. Make it use a LAN, and do port-forwarding and proxying through a box that knows about the multiple uplinks, and handles the switch-over when one of them goes down. I don't see how it might be easier with IPv4 than with IPv6.
In the IPv6 world, this is pretty much what you have to do. A whole lot of extra complexity and expense that you didn't have previously.
And IPv6 has the benefit of a significantly simpler 1:1 NAT.
The answer in this case ends up being solutions like explicit web proxies, or alternatively a VPN concentrator or the like from which you can receive a routable prefix delegation, and then run multiple tunnels to satisfy your own availability or policy routing needs. Either way, you’re building some complex infrastructure to overcome regressions imposed upon you at layer 3.
That doesn't solve the problem. DNS remains broken until each and every device, assuming VERY generously that it is capable of dynamic DNS at all, realises that one of its prefixes has disappeared and it updates its DNS records. With DNS TTL and common default timeouts for prefix lifetime and router lifetime, that can take anywhere from 30 minutes to 30 days.
> and firewall rules should be on the subnet boundary in this scenario, any decent firewall (including referee PFsense/OpnSense) support ACLs that follow IPv6 address changes.
This requires you to assign one VLAN per device, unless perhaps you've got lots of money, space, and power to buy high end switches that can do EVPN-VXLAN so that you can map MAC addresses to SGTs and filter on those instead.
What device on your office LAN should maintain its own DNS records? Advertise your own caching DNS server over DHCP(6), give its responses a short TTL (10 sec), make it expire the relevant entries, or the whole cache, when one of your links goes down. I suppose dnsmasq should handle this easily.
It seems that the discussion turned away from a multi-homed setup (pooling the bandwidths of two normally reliable links) to an HA/failover setup (with two unreliable links, each regularly down).
It either needs to be able to update DNS by itself (a la Active Directory), or it needs to be able to give the DHCP server a sensible hostname in order for DHCP to make this update on its behalf, which most IoT devices cannot.
People like you talking about IPv6 have the same vibe as someone bewildered by the fact that 99.9% of people can’t explain even the most basic equation of differential or integral calculus. That bewilderment is ignorance.
"Easy" is meant in that context. The people acting like the IPv4 version is easy.
So your second paragraph doesn't fit the situation at all.
"The shit about IPv6" is a mess of approaches that even the biggest fanboys can't agree on and are even less available on equipment used by people in prod.
IPv6 has failed wide adoption in 30 decades, calling it "easy" is outright denying the reality and shows the utter dumb obliviousness of people trying to push it and failing to realize where the issues are.
Not an issue in ipv4 because ARP isn't IPv4 so IP traffic shaping ignores it automatically.
Android doesn't support DHCPv6 so I can't tell it my preferred NTP server, and Android silently ignores your local DNS server if it is advertised with a IPv4 address and the Android device got a IPv6 address.
Without DHCPv6 then dynamic DNS is required for all servers. Even a 56 bit prefix is too much to remember, especially when it changes every week. So then you need to install and configure a dynamic DNS client on all servers in your network.
This is not even that unreasonable. Sadly, the number of IP devices in the world by now far exceeds the IPv4 address space, and other folks want to do something about that. They hope the world won't freeze but would sort of progress.
It’s not hard for people who get an appropriate education and put some effort into it. Your lack of education is not my ignorance.
The difficulty of setting IPv6 up at your house vs. the needs of a multi-homed, geographically diverse enterprise couldn't be more dissimilar.
I'd lay off the judgment a bit.
BTW a homelab often tries to imitate more complex setups, in order to be a learning experience. Can these difficulties be modelled there?
all of it ipv4 based. ipv6 maybe in distant future somewhere on the edge in case our clients will demand in.
inside our network - probably not going to happen
Public-interfacing parts can (and should) support IPv6, but I don't see much trouble exposing your public HTTP servers (and maybe mail servers) using IPv6, because most likely your hosting / cloud providers do 99.9% of it already, out of the box (unless it's AWS, haha), and the rare remaining cases, like, I don't know, a custom VPN gateway, are not such a big deal to handle.
amount of work to support ipv6 on the edge will be very big and none of our clients asked for it as far as i know.
the only time we discussed it, it's when we were getting fedramp certification. because of this https://www.gsa.gov/directives-library/internet-protocol-ver...
This is neither hard nor expensive.
Mind you, our team discussed this numerous times over a few years and never came up with a solution that didn't look like it would require us to completely fork-lift what we were doing. The whole team was FOR getting us to v6, so there was no dogmatic opposition.
Consider this:
25k employee company. Four main datacenter hubs spread out across the USA with 200 remote offices evenly dual-homed into any two of the four.
All four of the DCs had multi-ISP Internet access advertising their separate v4 blocks and hosting Internet services. The default-route was redistributed into the IGP from only two locations, site A and B. e.g. two of the four DCs were egress for Internet traffic from the population of users and all non-internet-facing servers. IGP metrics were gently massaged as to fairly equally use of both sites.
All outbound traffic flowed naturally out of the eastern or western sites based on IGP metrics. This afforded us a tertiary failover for outbound traffic in the event that both of the Internet links into one of the two egress sites was down. e.g., if both of site A's links (say, level-3 and att) were down, the route through site A was lost, and all the egress traffic was then routed out site B (and vice-versa). This worked well with ipv4 because we used NAT to masquerade all the internal v4 space as site X's public egress block. Therefore all the return traffic was routed appropriately.
BGP advertisements were either as-path prepended or supernetted (don't remember which) such that if site A went down, site B, C, or D would get its traffic, and tunnel it via GRE to the appropriate DC hub's external segment.
The difficulty was that traffic absolutely had to flow symmetrically because of the firewalls in place, and easily could for v4 because NAT was happening at every edge.
With v6 it just didn't seem like there was any way to achieve the same routing architecture / flexibility, particularly with multi-homing into geographically disparate sites.
I'm not sure anymore where we landed, but I remember it being effectively insurmountable. I don't think it was difficult for Internet-hosted services, but the effort seemed absolutely not worth it for everything on the inside of the network.
That’s before you go on to using PBR. I want to route traffic with different dscp via different routes.
Ultimately I want the rout g to be handled by the network, not by the client.
IPv4 and nat makes that a breeze.
edit Less flippantly, what are you wanting to base the routing rule on? What's your ipv4 routing rule?
DSCP is allowed in ipv6.
https://www.juniper.net/documentation/us/en/software/junos/c...
The "proper" way would be to get your own ASN and use BGP to route the traffic.
If you're wanting to use a secondary WAN link as a backup for when the other goes down you could have the backup link's LAN have a lower priority. (So I guess hope everything implements RFC 4191 like you said).
You can use NAT66/NPTv6 if you want (though it's icky I guess).
How are you doing it currently?
Sadly my 4g provider will not peer via bgp with me, even if I could provide an AS and Sufficiently large IP range.
I think my home ISP will actually peer with me, but I’d have to tunnel to them over my non-fibre connection, and there’s reduced resilience in that case.
At work that wouldn’t help at all, there are very few providers for many of our branch offices.
So once again ipv6 only works with “icky” nat, or on simple 1990s style connections, and not in the real world of multiple providers. Now sure I can do npt which means I don’t need to keep track of state, but then if I didn’t keep track of state I lose the benefits of a stateful firewall.
As such the only benefits of nat on v6 is that source ports will never need to change even if client 1 and client 2 both send to server 1 port 1234 from source port 5555. This helps with a handful of crappy protocols which embed the layer 4 data (port number) in a layer 6 or 7 protocol.
In the case of pfSense this is a recent change. It was not supported when I migrated away from it less than five years ago.
I am thinking that since an option starts with 2 bytes and everything must be padded to a multiple of 4 bytes, we can add 16 bytes to the packet, which would hold 7 extra address bytes per source and destination, giving us 11 byte addresses. ISPs would be given a bunch of 4-byte toplevel addresses and can generate 7-byte suffixes dynamically for their subscribers, in a way that is almost the same as CGNAT used today but without all the problems that has.
Most routers will only need to be updated to pass along the option and otherwise route as normal, because the top level address is already enough to route the packet to the ISP's routers. Then only at the edge will you need to do extra work to route the packet to the host. Not setting the option would be equivalent to setting it to all 0s, so all existing public hosts will be automatically addressable with the new scheme.
There will of course need to be a lot more work done for DNS, DHCP, syntax in programs, etc, but it would be a much easier and more gradual transition than IPv6 is demanding.
Plus, it's only 2048x the address space. It's within the realm of possibility that we will need to upgrade again once this place is swarming with robots.
Then the government could, for example, limit criminals' access to the internet by mandating that their packets be dropped on most major ISPs, or at least deprioritised.
I suspect by "incredibly conservative" you mean "backwards compatible", which... no. You can't make an addressing extension backwards compatible with hardware that doesn't read all of the address. Of course, we did that anyway with CGNAT, and predictably it causes huge problems with end-to-end connectivity, which is the whole point of IPv6. You're probably thinking more along the lines of an explicit "extension addressing header" for v4. Problem is, that'd mean a more awkward version of IPv6's /64 address split[0], combined with all sorts of annoying connectivity problems. The same corporate middleboxes that refuse to upgrade to IPv6 also choke on anything that isn't TCP traffic to ports 80 and 443. So you'd need Happy Eyeballs style racing between CGNAT IPv4 and "extended IPv4".
Also, that would just be a worse version of 6in4. Because they also thought of just tunneling IPv6 traffic in IPv4 links. I don't think you understand how incredibly conservative IPv6 actually is.
The problem with "incredibly conservative" IP extensions is that nothing beats the conservatism of doing literally nothing. IT infrastructure is never ripped out and replaced unless there is a business case for doing so. The current problem with IPv6 adoption is that nobody has yet said "let's stop processing IPv4 traffic", they've only said "let's get more dual-stack hosts online", which is a process that only asymptotes to 100% IPv6, and never reaches it.
IPv4 was not the first version of the Internet protocol. That honor goes to Network Control Protocol (NCP). The reason why we don't have an asymptotic long tail of Internet hosts still demanding NCP connectivity is because this was back when "having a connection to the Internet" meant "having a connection to ARPANET". The US military could just refuse to process NCP packets and actively did this to force people onto IPv4. Now imagine if someone big like Google said "we're going to stop accepting IPv4 connections" - people would jump onto v6 immediately.
[0] Let's say we add a 32-bit extension header onto IPv4
But that baggage is a huge part of the problem. Almost nothing you know about IPv4 applies when you switch to IPv6, and most of us found that out the hard way when we tried to make the switch. Leaves a pretty bad taste in your mouth.
The things I need to think about are precisely the things that changed radically. Firewall rules aren't the same due to prefix changes and no NAT. DHCP isn't the same, DNS isn't quite the same, distributing NTP servers isn't the same.
Almost nothing of what I knew about configuring my home router for IPv4 has transferred to IPv6 configuration.
Also a nitpick: switching is irrelevant here, that’s L2. L2 doesn’t even know what’s an IP address :)
There was some dude on YouTube that resurrected the first Ethernet bridge (which was built for thicknet) - I recall even that worked with IPv6.
This is exactly what I'm talking about. When you have problems with your IP network, that's the first thing you try and figure out, "what's my address? Why is that my address? Did it change? If so, why? Are other devices able to get packets? What are their addresses? Why can those addresses get packets but this address can't?"
Mobile carriers have done that between consumer devices and network towers. That forced a lot of innovation (including tools like better DNS64 and "happy eyeballs" protocols) and network stack hardening.
The roll out of out CGNAT in some cases is "let's drop IPv4 traffic randomly" and "happy eyeballs" in consumer devices is transparently driving a lot of consumer traffic to IPv6.
This is why mobile and consumer devices are leading the pack on IPv6 adoption.
It's maybe not all of Google that next needs to say "we're going to stop accepting IPv4 traffic", it's maybe more specifically GCP (and AWS and Azure) that need to do that to drive the non-consumer IPv6 push we need. The next best thing would be for all the cloud providers to at least start raising IPv4 address prices until their clients start to feel them.
One of the giant CDNs translates all IPv4 traffic to IPv6 at the edge (stateless NAT46) and is IPv6-only in its core network (for one of its primary product networks; like everybody they have multiple networks.)
IPv6 is a success IMHO because it is used in so many places. Google’s IPv6 traffic graph shows close to 50% adoption and still trending up. We can’t possibly expect the world to be near 100% overnight… the internet is a big place with the whole spectrum of humans influencing IT; There will always be someone who will cling to IPv4 for dear life.
The end game will be a cryptographically large address space allocated based on some cryptographic operation, rather than a committee carving up the space arbitrarily.
Tor already does this, addresses allocation is not a problem. I think they used to use hashes, but now use Ed25519 public keys. Obviously, Tor is not suitable for most tasks. No one should have to pay for the extra latency if they don't need the anonymity.
The real problem is routing in these address spaces, and there have been a few projects like CJDNS which try to solve it.
Oh and btw, your address is now 9245593924 Oak St.
Until somebody turned off the lights, that is. It is not much fun arguing with yourself in the dark.
I think that's what needed and needs to be done here. I will agree with the IPv4 advocates on one thing: IPv6 adoption has been slow in part because it doesn't work like IPv4 + kludges. That is the point. Clinging to IPv4 standard practices while you switch is just going to make you miserable.
In 2006, the hesitation to go to IPv6 made sense. Support was spotty. In 2026 it does not. IPv6 support is now more than adequate, and a clean cut will force the stragglers to get their asses in gear in a hurry ("fix your IPv6 support RFN or enjoy nobody using your product"). Change is painful, learning new stuff when you were getting by just fine on the old stuff is painful, I get it. But it will happen whether you like it or not. Why not just get it over with?
I finally made the switch to IPv6 last year, and I wouldn't go back.
The pain of change is real, but mercifully, it doesn't last. Within a year this debate will seem quaint.
I get the feeling it's another 5-10 years before "not getting around to ipv6" will actually be a mistake in that space...
There are number of embedded OSes and devices that do not have firewalls nor the ability to disable network ports. Example of these invisible world items are motors, servos, PLCs, and label printers that get configured over IP. These devices do the bare minimum to get the IP stack up and running. These UI tools also need to be updated for allowing configuring an IPv6 address.
I would love to leave IPv4 and move fully to IPv6. Currently it is not cost effect to do so at scale. Companies do not want to spend money on the extra hardware to allow their IPv4 devices to talk IPv6 when they can save that money and keep running IPv4. Nor do they want to spend money on newer hardware. I still have clients running Windows XP Embedded, hopefully air gaped, in the automation world.
*You would be surprised on the number of large corporate IT managers that rather have a completely open label printer connected directly to their network instead of bridged behind a state full firewall running Windows or Linux hosting the main product.
So I either need to use ipv6 + kludges or ipv4 + kludges. ipv4 is obviously easier and more reliable at that point, it's a no brainer.
Any sort of hot spot / bridge faces the same problem.
Now RFC 9663 is supposed to help here but guess what? It's only like a year old and barely exists. Not 20 years.
It's not that change is painful, it's the ipv6's original design of a shallow depth network was just... bad. Bolting on RFCs to fix it is taking a long time.
Youtuber apalrd periodically revisits the Ubiquiti Unifi devices to see if they finally support IPv6 and he concluded it still doesn't work correctly.
The linked comment from Ubiquiti acknowledges they're still trying to improve the situation : https://www.youtube.com/watch?v=KZpJvpm1Ris&lc=UgwXlto--2NbO...
EDIT add: A lot of home users also like Ubiquiti ecosystem for local recording security cameras without a cloud subscription. Another competitor like Reolink with local capability also doesn't support IPv6: https://support.reolink.com/hc/en-us/articles/900000645446-D...
The practical home usage of deploying IPv6 depends on combination of the ISP, the devices you want to use, software stack, etc.
Obviously the gateway or router missing proper v6 support is an issue and a bit surprising ubt hasn't done a good job.
Even my mid range TP-Link Archer I had 10 years ago properly supported IPv6
As with IPv4/IPv6, with Python 2.7/3 you had, even at the very end, a group of stubborn maintainers who didn't put in the effort to transition.
The hard end of Python 2.7 support took care of all that in a hurry.
There are no ISP providing ipv6 for home and mobile users here in hong kong
Mobile providers have been the first and most aggressive to migrate to IPv6. Probably helped along by the cost and difficulty of running CGNATs when your network clients are constantly moving around. At least in the UK all the mobile providers are IPv6, and I think a handful are IPv6 only.
I do use it often, at least for Internet communication (I haven't checked recently to see what my traffic split is between v4/v6, but it's probably on the verge of tilting in favor of v6, if not already there), but I just can't see using it for my internal network anytime soon.
The people feeling the pain would not be in any position to fix the problem, and their experience will be that your site is down which leads to support burden and reputation risk for your product. If your support tells me to switch ISPs I'm going to roll my eyes and find another product that works.
_Everybody_ would rush and make sure to switch everything to IPv6.
Maybe not in the strict sense, but it kind of has.
In the enterprises I've worked in the past decade with IPv6 running, at least 75% of the Internet traffic is IPv6. In my discussions with other engineers managing large networks, they seem to be seeing more or less that same figure.
The problem is that virtually nobody knows IPv6. I regularly bring up IPv6 in engineers' circles and I'm often the only one who knows much about it. And so, I have doubts about it's long-term future, except for edge cases. I figure some clever scheme utilizing IPv4 and probably NAT will come around at some point.
https://auctions.ipv4.global/prior-sales
Prices have been going down in nonimal terms for years, let alone real terms. In terms of investment they're a terrible asset.
That doesn't seem terrible.
>Have an IPv4 assignment from ARIN or one of its predecessors
>Intend to immediately be IPv6 multi-homed
>Have 13 end sites (offices, data centers, etc.) within one year
>Use 2,000 IPv6 addresses within one year
>Use 200 /64 subnets within one year
Seems like they discourage individuals from getting allocations for their own personal use.
I only know anything about RIPE policies but I gather the PI address processes and fees are very similar between RIPE and ARIN. RIPE has many members that are willing to handle address allocations for the RIPE fee plus 20% (so 60€ per year) and without bundling any other services.
E.G. Comcast should be REQUIRED to give my OWN router a /56 or better, not a /60 because they waste a whole nibble of netmask at the cable modem which will _never_ talk to anything other than Comcast or my own Gateway.
Ultimately, as a regular person requesting IPv6 space you'd just ask your ISP, which can get practically as much as they want for free by submitting these kinds of requests. Meanwhile, for IPv4 space they're going to have a harder and harder time getting you additional space and chances are be unwilling to give it free/cheap.
In real life these requests don't lead to IPv6 allocation, no matter how they're asked or how often. Here are a few of the responses I've received just this year.
"At this time we are not able to provide a IPv6 unfortunately."
"We regret to inform you that, at this time, we do not offer IPv6 support."
"I wanted to inform you that IPv6 is currently not available"
Past that: Over 15yrs of asking various ISPs (large and small) to make allocations available, none of us ever budged the IPv6 needle.
I think this is representative of every IPv6 deployment. You get it or you don't. If it isn't available to you, asking won't make any difference.
FTR we have 6 wireline ISP here. Cable has IPv6, the 5 fiber operators do not.
Does me renting a server in a DC count as multi homing? Bridging my network to my friend's place over wireguard? Doubtful tbh
It really depends on what you're trying to achieve by having a direct IPv6 allocation...
If, as ARIN claims, ipv6 scarcity is not an issue then it's very frustrating to deny me the ability to get my own chunk of space for my own purposes.
It shouldn't matter what I plan to do with it.
The official docs of the RIRs are "non-commercial guides for IPv6 allocation", too.
Multiple websites can have the exact same DNS record and live on the same physical server / IP address, but the HTTP(S) request must specify what host name it is actually requesting, so the server knows how to serve it.
I challenge you to find:
1. A hotel in the US that provides IPv6. I have NEVER been in one, and I once stayed in a hotel (in Mountain View, CA) that was giving out public IPv4 addresses.
2. An easier task: a SIP provider that has IPv6 (in the US). You know, for the VoIP that is supposed to be a poster child of end-to-end connectivity.
What about those without IPv6 running?
Anyway, in the enterprises I've worked in the past decade - of course, another anecdote - not once has anyone ever specified an IPv6 address of anything. Inside the organization or outside of it.
everything fit's nicely in the 10.0.0.0/8 range
in my many decades of enterprise infrastructure, no-one has ever mentioned IP6 either.
why would they, whats the business case?
Except during a merger/acquisition and both companies have 10.0.0.0/24 in their OSPF or IS-IS topology.
Except for when it doesn't.
If you just use that space as a flat range, it is almost certainly more than enough. But if you split it up in multiple levels of subnets, you can run into difficulties balancing having enough subnets and having enough space in each subnet.
IPv6 is much more stable on what you can use. fc00::/7 is actually private use.
In short: The market has already decided and it's private. It's far from the first time an unofficial arrangement is the de facto standard.
I don't claim IPv6 isn't used anywhere, or even that it's not used a lot.
With subnetting needs, possibly dealing with VPNs to other networks that might use 10./8, ISPs that might use 10./8 instead of CGNAT space (100.64./10), even the total incompetence of some contractors was not reducing how IPv4 was a problem.
And that's before you hit the part where Microsoft products have been IPv6 First since ~2008 and there are entire feature sets that are very interesting to bigger companies (like well integrated always-on vpn for laptops) that require working v6
if you've never run in to this, then sorry, you've not been in an enterprise, you're in a mom 'n pop shop cosplaying as enterprise.
If you deploy IPv6 correctly, you shouldn't have to disclose IPv6 addresses to users inside or out -- DNS keeps the address literals abstract, hidden from users.
>In the enterprises I've worked in the past decade with IPv6 running, at least 75% of the Internet traffic is IPv6.
Nobody cares about those. What matters is if my device has an IPv6 address assigned.
> Nobody cares about [that]. What matters is if my device has an IPv6 address assigned.
This seems to be the weird dichotomy in these comments. Some people are arguing from the position that is absolutely everywhere and is doing great.
Others are saying since their machine doesn’t show it it’s dead and no one cares.
Is there a term for this? A successful failure? A failed success?
Kind of odd.
The other thing I have seen is that engineers make things complicated. Normal person has IPv6 enabled by default or enables it in router, and it just works and they never notice. Engineers want to configure things manually, but IPv6 is hard if fight against the dynamic defaults.
Here’s a prediction. Linux on the desktop will have >50% penetration well before IPv6 does.
No, it isn't. Everyone here has the causality backwards. We don't know it because we've never needed to know it, and we've never needed to know it because it's not really required for anything (i.e. the cost of adopting/learning it > benefit).
This has been a frustrating HN discussion to read, to be honest, because the consensus view strikes me as so off base. It's not that IPv6 has been miscommunicated, or that it hasn't been taught enough to undergrads. It's that it has been designed with virtually no incentives to encourage people to actually adopt it, with the entirely predictable consequence that no one adopted it. Therefore, none of us need to know it, schools don't need to teach it, etc.
Folk are internalising the wrong lesson here. Incentives matter. No amount of mandated IPv6 instruction or well-intentioned blog posts explaining IPv6 are going to change anyone's incentive structure. And then when those things fail, there's a predictable and tiresome tendency to blame the users for not switching.
If you want people to adopt new tech, make it actually do something new. Give people some reason to want to switch. "It mostly does the same thing as the old tech did, but it also takes effort and money to learn it / switch to it" is a terrible pitch, with entirely predictable consequences, and it's far too common in technical circles.
As the sibling comment pointed out: it's very close to 50% adoption, you just don't see it https://www.google.com/intl/en/ipv6/statistics.html
Could you be specific about what the misconceptions are?
2. The response is still too wordy, generic, and boring. So LLMs are not really better players, at least for now.
3. With LLMs, you can produce a ton of text much faster than it can be read. Whereas the dynamic is reversed for ordinary writing. By writing this by hand, I am doing you a favor by spending more time on this comment than you will. But by reading your LLM output I am doing you a favor by spending more time reading than you did generating.
You could probably get away with using an LLM here by copying the response and then cutting down 90% of it. But at that point it would be better to just restate the points yourself in your own words.
EDITED TO ADD:
> by reading your LLM output I am doing you a favor by spending more time reading than you did generating
How could my respondent (presumably on whose behalf you are making the argument) possibly be doing me a favour when they asked the question? Is it each of our responsibility to go to some lengths to spoon feed one another when others don’t deign to feed themselves?
And yet there is still only "you doing it wrong, and I won't tell you how to do it right"
It doesn't matter what problems it supposed to solve if it doesn't work.
My have certain shortcomings: it doesn't assign dns names to hosts and doesn't configure firewall rules
There is a heck of a Dunning–Kruger joke to be made here.
Future proofing it by jumping straight to 128 bits instead of 64. 64 would have been fine. Even with a load factor of 1:1000 by assigning semantics to ranges of IP addresses, 64 bit addressing is still enough addresses for 10 million devices per person.
If we become a galactic empire, we will have to replace the Web anyway because every interaction will have to be a standalone app or edge networking that doesn’t need to hear back from the central office for minutes, hours, days anyway. We could NAT every planet and go on forever.
But because you have two independent unique parts, you need twice as many bits, so 64+64=128 bits. It simplifies routing and address allocation, at the cost of 16 bytes per packet compared to 64 bit addresses.
That we could use IPv6 on galactic empires is an added bonus, but not really the reason.
My ISP router supports IPv6 but blocks all incoming connections by default, which is kind of like what NAT does as a side effect.
It sounds like insanity because we tend to assume that no NAT means no firewall, because NAT has some firewall-like properties, and on the most basic networks, that's the only "firewall" there is. But none of the security features of "NAT as a firewall" are exclusive to IPv4, in fact, IPv6 has an advantage because the much larger address space makes a full scan practically impossible.
This trips up a lot of people, and I think it's because NAT was probably their first real exposure to networking. When that happens, you end up building all your mental models around NAT as the baseline, even though NAT itself is really just a workaround for address space limitations.
What's interesting is that someone with no networking background who thinks of it like a postal system (packets are letters that get forwarded through various routing centers from source to destination) would actually have a more accurate mental model of how IP networking fundamentally works. The NAT-centric view we all learned first can actually make the basics harder to understand, not easier.
Eh, what?
My entire justification for getting rid of NAT is *because* a default-deny-inbound firewall policy should exist, and NAT is a network patch that functions as a hacky firewall at the consumer level.
This hasn’t been the case for 20 years. Privacy Extensions solved that, and every SLAAC implementation supports them.
128 bit is like the least of adoption issues and basically meaningless difference vs 64.
But it shows weird priorities when they decided 128 then immediately wasted half of it on host part just to achieve "globally unique" host part that isn't really all that useful characteristic of the protocol.
non-routed prefixes are a limitation imposed by the ISP the the user can't address.
That's the essential part of self-configured addresses in IPv6 that does away with DHCP in most cases. DHCP is a stateful system that has to track every device's addresses individually. You don't need that with IPv6 thanks to this.
Need I remind you that option to push DNS server (which is pretty fucking important option!) was added to IPv6 standard only in 2007 ?
Like, someone decided "yeah have that magical stateless autoconfig thing" and didn't figure out that basic options like DNS, or less common but still VERY useful like the PXE stuff, or NTP server, routes and dozen others DHCP does? (there are security implications too but DHCP wasn't great here too)
IPv6 in its original format was a joke and stateless configuration is more or less pointless excercise aside from link-local adresses but those could be only exception where stateless runs
v6 restores the end-to-end principle and reduces network complexity once you go v6 only. Not more NAT traversal problems, no need to deal with STUN/TURN, small networks get even simpler with no need for a statefull DHCP server.
Sticking with only v4 space also artificially increases the cost of starting new networks and services because you have to buy space from the entrench IP save owners (unless we change the rules are start charging fees to legacy networks and reclaiming unused or poorly utilized space). Those higher barriers to entry hurt innovation and competition.
So v6 solves several technical and policies issues with the Internet, and maybe that's why we haven't seen speedy adoption. Because people have networks that exist today, some have paid a lot of money for IPv4 space and they want to make the most of that investment.
They don't really have an incentive to implement V6 unless things start to break without it.
I don't think v6 has been a failure half of all internet traffic runs on it! It powers the major cell phone networks, and large tech companies like meta have even gone v6 only in their data centers.
What networks are v6 only today?
> So v6 solves several technical and policies issues with the Internet,
If it's not used it doesn't solve anything
> They don't really have an incentive to implement V6 unless things start to break without it
Exactly my point
Mostly mobile networks.
> If it's not used it doesn't solve anything
It's used by literally billions of devices.
Besides all of those, you are still most likely going to encounter network slowdowns when you have IPv6 because it's gonna try IPv6 and fail to load the target website since even website that have an AAAA record are usually inaccessible over v6 for some reason. Oh and firewall is a set of separate configurations on v4 and v6 (iptables vs ip6tables, having to reconfigure it on nftables for both, etc..) at least ufw handles it nicely nowadays. I had IPv6 enabled for a month about three months ago and all I experienced was slowdowns (due to websites having to fall back to v4) and things not working (such as my failover setup - global scope vs local scope). It's back to disabled in my home network.
I use hyperoptic in the UK, if you replace the original router (which reserves the external 443 port for itself, i.e. no one sophisticated would keep it), there seems to be no way to get a v6 address. This is pure incompetence and carelessness. Like ISPs allowing their network to send packets spoofing IPs from outside their network. Add to that foreign ISPs (which means that even if your own network supports v6, you need v4 support when you are on holidays/travelling), and you have a situation where v4 cannot simply be switched off.
So for a website, what is the point of supporting v6 if v4 is never going away?
e.g. Getting a unique address would be way more risky with 64 bits (there's a reason UUIDs are 128 bits too!), even before considering the network:interface split.
It's hard to disagree with your point since 64 would definitely have been better than the 32 we have. I'm not convinced the choice of going for 128 bits posed any real challenge to adoption though.
By raising the barrier to entry so high we guaranteed the features would likely never be needed.
the goal being to support a model where one could support multiple prefixes to handle the common case of multiple internet connections. more importantly to allow providers to shuffle the address space around without having to coordinate with the end organization. this was perceived to be necessary to prevent the v6 address space from accruing segmentation.
Keep in mind that SLAAC isn't. Modern IPv6 stacks use privacy addresses, so they still need to run the address collision detection.
There's also a proposal to have SLAAC with longer prefixes, because otherwise you need to use DHCP-PD if you want to have subnetting in IPv6.
In Asia they've implemented v6 everywhere pretty much because their v4 allocation is woefully insufficient. APNIC has like 4 billion people in it but less IP space than ARIN, with a population of less than 500 million.
If the ISP is IPv6-first, you bet that their customers are using it in their home WiFi.
In my experience it's actually the large enterprises that are having issues.
This is the obvious and only key to this puzzle.
We tech nerds have this mad idea that everyone will want to spend time and money adapting to new standards because they're technically better in some abstract way, and so we do absolutely no work to create incentives for anyone to switch. Often, the new standard is not (yet) even functionally equivalent to the old one (e.g. Wayland), just to make doubly sure the switch will be as difficult and undesirable for end users as possible.
And when the absolutely inevitable consequences occur - stakeholders do not want to invest in switching to or developing for new standards that give them zero incentive to do so - there's a silly finger pointing game, as though everyone was supposed to switch, and they've failed to do so. Which is, of course, absurd. People don't owe us compliance.
Do not expect to be able to successfully shift behaviour unless you give people incentives - reasons they would want to switch, not just reasons you want them to switch.
I had mentioned some of that in my post: https://ssg.dev/ipv6-for-the-remotely-interested-af214dd06aa...
Just as an example google's public DNS is 2001:4860:4860::8888 because their v4 dns is 8.8.8.8.
The reason it's not winning in the other places is because Network engineers hate IP version 6 as a rule .
It makes sense that it's won on mobile. In that scenario, NATs are stupid and lots of addresses are needed.
In the data center, fewer addresses are needed and NATs are vital for security.
The two worst uses of the internet.
I find it useful, mine does change periodically, but I just have a script that Updates DNS when it changes:
nsupdate -v -y "${KEY_ALGO}:${KEY_NAME}:${KEY_SECRET}" <<EOF
server $DNS_SERVER
zone $ZONE
update delete $RECORD AAAA
update add $RECORD 300 AAAA $CURRENT_IP
show
send
EOF
The huge difference from the IPv4 world is that the procedure for generating your /48 ULA prefix ensures that it's very, very unlikely that you will get the same prefix as anyone else. So, if everyone follows the procedure, pretty much noone has to worry about colliding with anyone else's network.
Following the procedure has benefits. For example, VPN providers who want to use IPv6 NAT can do that without interfering with the LAN addressing of the host they're deployed to... companies that merge their networking infrastructure together can spend far less (or even zero) time on internal network renumbering... [1] etc, etc, etc.
[0] And link-local addresses are the equivalent of 169.254.0.0/16 space.
[1] Seriously, like a year after one BigCo merger I was subject to, IT had still not fully merged together the two company's networks, and was still in the process of relocating or decommissioning internal systems in order to deal with IPv4 address space constraints. Had they both used ULA everywhere it was possible to do so, they could have immediately gotten into the infosec compliance and cost-cutting part of the network merging, rather than still being mired in the technical and political headaches forced upon them by grossly insufficient address space.
https://blog.apnic.net/2022/05/16/ula-is-broken-in-dual-stac...
Nope, it works just fine. I use it for stable local addressing and LAN host AAAA records and let my ISP-delegated global prefix drift as my ISP wishes it to.
And -as it happens- the prose in that article about source address selection is incorrect.
On Linux, source address preference appears to be application-specific. For example, curl prefers IPv6 addresses, and falls back to IPv4 if the v6 connection fails. I checked just now by removing my globally-assigned IPv6 address, and capturing the traffic created by executing 'curl https://www.google.com'. I know for a fact that BIND 9 prefers non-link-local IPv6 source addresses over IPv4 addresses because until I set up my home-built router to reject Internet-bound traffic coming from my ULA, a sufficiently-long failure of the DHCPv6 server run by my ISP would cause name resolution to get very, very, very slow when the global prefix expired and BIND started using its host's ULA as a source address and my router dutifully relayed that traffic into my ISP's black hole. I'm certain that very many applications unconditionally prefer non-link-local IPv6 addresses over IPv4 ones. You might also care to pay attention to this comment and its publication date: [0]
OTOH, Firefox prefers IPv4 connections in that scenario and doesn't even attempt a v6 connection. I assume Chrome is the same way.
And, that article suggests GUA space as a replacement for ULA space:
> All of these are serious pitfalls that arise when attempting to use ULA. The simple and more elegant answer is to simply leverage GUAs.
Which... uh... no. I'd have to go through my local RIR to get an allocation, and then negotiate with my ISP to get it routed. Given that I'd have to go through ARIN because I'm in the US, and I have a boring residential account with my ISP, neither of those things will ever happen. The entire point of ULA is that no coordination with external entities is required to do network-local addressing.
Also, the documentation that that article links to to discourage people from deploying NAT66 is almost literally "It's exactly as complicated as NAT44. Why do it when you can get global IPv6 addresses?!?", which isn't a useful complaint when your intent is to exactly replicate what you get from IPv4 NAT in an IPv6 world. I agree that globally-routable addresses are better, but if your site admin demands (for whatever reason) that you not have them, then -because of the collision-avoidance property of the ULA prefix generation procedure- you're better off than with IPv4 NAT.
[0] <https://blog.apnic.net/2022/05/16/ula-is-broken-in-dual-stac...>
I also have a dynamic IPv6 prefix. That one changes at least once a week, regardless.
Sadly, this happened despite me specifically requesting the same address as always. That caused me some grief. But it's not common.
https://www.spectrum.net/support/internet/ipv6-faq
> IPv6 is available today with an IPv6 capable modem in the majority of Spectrum’s footprint.
For home internet service I would prefer to pay extra for a better service, it's too important to try to penny-pinch 0.1% of my income on it.
But then I live in a capitalist country where there's competition, I believe some countries you don't get a choice.
The more practical thing to look for is that they aim to upgrade it based on need, instead of arbitrarily throttling the users.
My prefix is tied to the mac address of the device that's connected to the PON.
It should have been ipv4 with extra optional bits, so you could have the same rules and everything for both stacks.
I turn it off because it's a risk having one of either stacks malconfigured.
IPv6 should've been a superset of IPv4, as in addresses are shared, not that you have a separate IPv4 and IPv6 address for your server.
Thread+ Matter, despite using a different radio, suffers from the same issue, since a border router is on the Wifi network, a smart bulb using Thread can theoretically access my PC.
Yes, I'm sure there are ways to fix this, but why have the problem in the first place?
Zigbee is entirely incompatible networking standard, and doesn't have this problem.
>It was doomed the moment you had to maintain two separate stacks
Pray, tell me, how are we supposed to extend IPv4 with another {insert a number here} bits without creating a new protocol (that neccessitates running two stacks)?
Suppose that you have an old computer that understands only 32 bit addresses -- good ol' IPv4. Let's name it 192.168.10.10.
It then receives a packet from another computer with hypothetical "IPv4+" support, 172.12.10.98.12.4.24.31... ...Wait a minute, it can't, because your old computer understands only 32 bit addresses!
What if we really forced it to receive the packet anyway? It will see that the packet is from 172.12.10.98, because once again, it understands 32 bit addresses only.
It then sends back the reply to... you guessed it, 172.12.10.98. Not 172.12.10.98.12.4.24.31.
Yeah,172.12.10.98.12.4.24.31 will never get its reply back.
Do you see why any "IPv4 with extra octets" proposal are doomed to begin with now?
How will you fix that? By gradually reinventing v6, one constraint at a time. You're trying to extend v4, so you can't avoid hitting all of the same limits v6 did when it tried to do the same thing. In the end you'll produce something that's exactly as hard to deploy as 6to4 is, but v6 already did 6to4 so you achieved nothing.
This is stuff that could be implemented in any ipv4 stack in some days of work.
IPv6 is overengineered, thats the reason why it's not adopted after 30 years.
>This is stuff that could be implemented in any ipv4 stack in some days of work.
The sysadmins across the world, who had to deal with decades-old, never-updated devices facepalmed in unison.
At least the other comment agreed that "IPv4+" hosts will never be able to talk to IPv4 hosts.
>IPv6 is overengineered, thats the reason why it's not adopted after 30 years.
It is already adopted in many countries. Don't blame the protocol for your countrymen's incompetence.
> "In fact, IPv4's continued viability is largely because IPv6 absorbed that growth pressure elsewhere – particularly in mobile, broadband, and cloud environments," he added. "In that sense, IPv6 succeeded where it was needed most, and must be regarded as a success."
Apparently it turns out IPv6 wasn't for me any way!
Because, it's not going away: You can talk all you want about how IPv6 should have been a more straightforward expansion of the address size, but this is all in the rear-view mirror at this point. IPv6 is going to be with us forever, you may as well get used to it. It's already everywhere in 5G deployments, ISP's like Comcast use it for 100% of their out-of-band management, China is making huge progress moving to it as part of their 5-year plan, India is progressing nicely in their transition, the list goes on. We're already way too far along in the transition to abandon it in favor of something else.
But it's not going to happen any quicker than we've seen, either: There's no urgency (no "must-have" use case) except for what organizations are imposing on themselves. Yeah, IPv4 addresses are more expensive, but you don't really need many of them as a business (you can get by with a small handful of public ones, and just using L7 load balancers and SNI for everything) nor as an ISP (CGNAT can get you a long way.)
So we have a situation where things are migrating very slowly, mainly only in places where it makes sense (mobile deployments, home ISP's where the users don't actually administer the network), and generally mostly for new deployments. This is a recipe for IPv4 to be around for a very, very long time. We're used to technology moving at breakneck pace, but that's only the case for the higher-level stuff. The core infrastructure like the internet protocol is likely the textbook example of slow-and-steady, and a case where it's actually not crazy to think of centuries-long timeframes for things.
[0] Barring any unforeseen black-swan events like a world war destroying all technology and having to rebuild from scratch or something. Or a competent international agreement to aggressively migrate to it (I don't know which is more likely.)
The world could pretty easily run on heavily NATed v4 for a long, long time.
At what point will we be allowed to say IPv6 hasn't failed? When the IPv4 internet finally switches off for good? It feels like no achievement is high enough for those who don't like IPv6 to change their minds. I would've thought making up 50% of internet traffic and 50% of end devices being on IPv6-only networks would be good Schelling points, but evidently they're not!
"IPv6 ... still hasn't taken over the world [after thirty years of deployment]." is a very different statement than "IPv6 has failed.".
Noone who has successfully extracted their head from their ass says that IPv6 has failed. It's widely deployed on the Internet, and on who knows how many corporate intranets and SOHO/home LANs.
IMO, it's stupid to ever consider turning off IPv4. There surely exist useful systems out there that will never be updated to work with IPv6.
I see IPv6 as an "IPv4 address pressure relief system". In the future, SOHO/home LANs can run servers on IPv6, datacenters can run servers mostly on IPv6 but also v4 if they really want, and SOHO/home networks can be behind an IPv4 CGN because all of their unsolicited inbound traffic will come over IPv6.
It's incredibly likely that the GP was referring to comments in this thread, which were indeed claiming that IPv6 has failed, despite the fact that its deployment has been steadily climbing up worldwide.
By the way...
>In the future, SOHO/home LANs can run servers on IPv6
The future is now. My web server is IPv6 only precisely due to the same reason you mentioned: my ISP has put me under a CGNAT. People can still connect to my website through the Cloudflare reverse proxy though (which I have only enabled for IPv4, IPv6 users get to enjoy direct connection).
One part of it is for some-to-many folks, yes, and the third is here for a distressingly large number of people (without the solid support of the second part). Do note that the future I outlined has three parts. ;)
I agree it's not a failure, but after 3 decades it's still frustratingly annoying to use at times.
https://learn.microsoft.com/en-us/troubleshoot/windows-serve...
Anyone sane would call a standard that remains annoying to use after 30 years a failure.
Does anyone have any success stories from the server side handling a situation like this? Looks like cloudflare switched to some kind of custom dynamic rate limiting based on like addresses, but it's unrealistic to expect everyone to be able to do such a thing.
We replaced records with tapes, tapes with more tapes, and more tapes with CDs before they, too, disappeared from the shelves in favor of streaming. Except that some stalwarts have successfully resurrected vinyl.
We replaced AM with FM, and analog radio with digital radio, then streaming. We replaced broadcast analog TV with digital, then cable and satelite, then streaming. Mostly.
None of these changes were backwards compatible, and all of them were meant for the general public. They took a while. They were successful.
The problem with IPv6 is that you don't get benefits. If the designed protocol needs an equivalent of big bang, it's doomed. ASCII->UTF8 didn't need big bang. x86 to Itanium needed big bang.
v6 is about as backwards compatible with v4 as it's possible to be. If you have a way to make it more backwards compatible then I'd love to hear it, but when I ask this all I ever get are things that don't work, or things that v6 already does.
But for another, the v4 space is available as a subset of the v6 space:
$ ping 64:ff9b::8.8.8.8
PING 64:ff9b::8.8.8.8(64:ff9b::808:808) 56 data bytes
64 bytes from 64:ff9b::808:808: icmp_seq=1 ttl=113 time=9.82 ms
127.0.0.1 needed to be a valid IPv6 address, along with all the others. Pick a particular prefix, say 0...* and any address with that would be extended to 128 bits. That would have been backwards compatible.
There is no possible way to design an address protocol with bigger addresses than v4 that a) makes v4 forward compatible with it, and b) can actually work. Feel free to suggest one.
> .0.0.1 needed to be a valid IPv6 address, along with all the others. Pick a particular prefix, say 0...* and any address with that would be extended to 128 bits
That prefix is ::ffff:0:0/96. 127.0.0.1 is ::ffff:127.0.0.1 (::ffff:7f00:1). 30 years and you still haven't realized v6 has this?
That doesn't mean that the limits of the old design won't hit anyway and force a switch off it.
The problem is that you can't use those bits to expand v4's address space, without taking all of the same steps v6 needed to do. v4 has no mechanism to get v4 hosts to understand extra address bits, wherever you put them.
Oh, that and the fact that IP addresses are stored in many more places than just the v4 packet header. Consider DNS, DHCP, ARP, gethostbyname(), struct sockaddr_in, databases using VARCHAR(15), etc etc etc. The packet header is only a tiny part of the story.
Now, I can simply restart my router (or cycle airplane mode on mobile) and get a new IPv4 that probably was used by bazillion people before me, or even along with me, and get a new account. So Google has to be very careful here, with IP-linked bans in order to not just ban the whole load of unconnected people just because they used the same IPv4 as me.
With IPv6, they could just ban my entire family and any guests that might have connected to my WiFi, forever.
I like the limitations of IPv4, thank you.
Only for the device identifier part of the address. Prefix that the ISP will allocate will remain static, unless ISP does rotate the prefix too, which they don't really have a need to, unless for privacy reasons. And knowing ISPs and demand for privacy, it's highly unlikely to happen.
> Further, user fingerprinting flourishes without IP addresses.
It does, but is still hard to do. Static IP prefix is going to make the heuristics much, much better.
Besides, evading most of the fingerprinting techniques is not that complicated - most of it is in the hands of the client. IPv6 adds something out of the hands of the client.
I don't want internet infrastructure to support this behavior. On contrary, I want it to resist it, and IPv4 does, to some extent, while IPv6 makes it much easier.
Only half joking, some UK MPs might actually consider this a reasonable thing considering how many ipv6s there are.
Not that it matters, really. As far as I'm aware, there were never any substantial deployments of this protocol.
What makes an ipv6 useful is that you can route to it. Since you will never be connected to the network. The network will never be able to route packets to you, making the whole thing a little pointless.
I'm thinking the gov issuing you an ipv6 address that you must use to connect to the internet. But it's also you're id too, since nearly all services are either online or getting pushed that way.
In my case, I administrate a small server at home, where I self host many services that are made available to myself, friends and families, over the internet.
In that context, IPv6, is SADLY (please note that I have NOTHING against IPv6), a limitation, even a nightmare to use.
Some programs do not handle IPv6 at all. Game servers for instance, do not support it, the one that I think about is: Arma 3. But there are many others
In 2025 (and 2026 too?), 4G (5G?) operators do not all route over IPv6 -> which means that if your domain only has a AAAA record, some people using 4G will not be able to access ANY of your services. This issue forced me to beg my ISP to obtain an IPv4 "fullstack" as they call it.
Without that IPv4 you have to go through some kind of tunneling (like Cloudflare) -> and guess what? Cloudflare sometimes crashes (it happened super recently remember?) and in that situation -> ALL your services accessible through the tunnel are "down" for your users. Plus, it is EXTREMELY unsatisfying to rely on an external private-owned service for a selfhosting project.
In almost ALL context IPv6 is seen as optional, additional, additional configuration and is NEVER the default. NEVER. Which means: more configuration, possibly more struggle.
Not all.
I operate site with IPv6 only origins behind cloudflare.
During the outage I manged to login to the dashboard after some time and remove cloudflare for nearly 2 hours, and traffic level stayed close to 50% during the IPv6 only period.
Nobody complained: those who did not have working IPv6 probably blamed it on cloudflare.
> Nobody complained: those who did not have working IPv6 probably blamed it on cloudflare.
You described a situation where the outage resulted in 50% of your customers were unable to reach you and you were unable to do anything about it. I don’t think this story is a win for IPv6, regardless of whether your customers blame CloudFlare or not.
50% is a very substantial retention rate.
The story here is not “ipv6 made my site resilient to CloudFlare outage”. It’s “50% of my customers can’t reach my site even when I turn off CloudFlare”.
And it's becoming difficult for people to do so precisely because of IPv4 addresses running out...
Weird. The past two ISPs I've had (Comcast and Monkeybrains) both had IPv6 enabled by default. I've looked at a bunch of SOHO networking gear and IPv6 is on by default. On every Linux and Windows system I've touched in the past ten, fifteen years you have to go significantly out of your way to disable IPv6.
> Some programs do not handle IPv6 at all. Game servers for instance, do not support it...
Depends on the game server. Many I run absolutely do.
Your complaints smell like you tried to run an IPv6-only client network, which would be an absolute nightmare. That's just a stupid thing for a SOHO network (and the networks that serve most corporate client hosts) to do. IPv4-only Internet hosts exist, so it's a no-brainer to provide IPv4 connectivity to clients.
On the other hand, running IPv6-only infrastructure networks can make a ton of sense. One very large such operator is Comcast, a US ISP.
I would love for IPv6 to actually take off but somehow it feels like we are still a decade away from ubiquitous adoption.
idk if arma3 does server discovery, but in case of manual ip input there some kind of OS-networking-level adapter should help. Usecase seems too obvious for something like that not to exist
Next year that chart will finally cross 50%. It was a mere 30% in 2030. Developing country mobile phone networks will continue to push it higher.
All we need to do is start having rich governments mandate IPv6, and also mandate IPv4 downtime as a punishment for those that don't comply / chaos engineering for the system as a whole. Then we can quickly finish the job.
consumer networks have significantly higher adoption rates compared to corporate/edu, and people are on vacations during summer
Well, to the extent the rich country laggards are institutional, then regulation should be more effective!
Yes, yes, we have privacy extensions, but you can still group those through higher-level fingerprinting. You don't get mixed traffic.
You can set it up so your devices can have two IPv6 addresses. The shifting address for external traffic, and a static one for local traffic. I think this is the default in many linux distros now.
The only wrinkle I ran into is that apparently ISPs are still reluctant to give out static IPv6 prefixes to residential customers. So you still need some kind of DDNS setup, which is lame.
Land lines internet have been IPv6 for more than a decade.
While developping custom IPv6 internet software I am not blocked by NAT anymore, real p2p fiesta, everything works as intended.
The real challenge now is IPv6 with fixed mobile internet address (not random as it is is now, it should be device uniq). That to replace for good the phone numbers (the challenge of international roaming... which is already done for phone numbers). The idea would be to avoid a third party centralized internet account->ipv6 mapping.
Don’t know about Matter though. If it requires the user to turn on IPv6 then it’s a user experience downgrade. It should just use IPv6 internally as an implementation detail.
Some routers can work as _relays_ between the Thread network and WiFi, but this is entirely optional.
Bonus: the relatively recent RFC 9686 that I hope will get some good traction: https://datatracker.ietf.org/doc/rfc9686/
Apparently it's "not how it's done" and we're "doing it wrong".
My SOHO equipment doesn't really support it either, so it's just as well, staying on IPv4 which does DHCP and solves that problem.
Not if you're on Android. https://issuetracker.google.com/issues/36949085
Windows in powershell:
SetNetIPv6Protocol -UseTemporaryAddresses Disabled
SetNetIPv6Protocol -RandomizeIdentifiers Disabled
sysctl net.ipv6.conf.all.use_tempaddr=0
ip6-privacy=0
ifconfig em0 inet6 -temporaryI think a lot of people assume privacy addresses are required. You can just not mess with them. Privacy is dead anyway.
And I want to connect to my machines without some stupid vpn or crappy cloud reverse tunneling service. Not everyone in the world wants to subscribe to some stupid SaaS service just to get functionality that comes by default with ipv6.
I think Silicon Valley is in a thought bubble and for people there ipv4 is plentiful and cheap. So good for them. However, the more these SaaS services delay ipv6 support, the more I pray to any deity out there I can move off these services permanently.
But here's a more thought-out design:
- register a well-known IPv6 prefix with 20 bits reserved for AS number
- so we'd have ${well_known_prefix}:${AS_number}:${customer_prefix}:${end_entity} (not necessarily that format for display, but just for the purpose of getting the idea across here)
- have DNS servers return AAAA RRs with the AS number filled in
- DNS servers should either have the correct AS numbers filled in their zones, or possibly could subscribe to the RPKI and use the RPKI for mapping ${well_known_prefix}:${all_zero_AS}:${customer_prefix}:* to AS numbers, then fill them in (this would require live signing if using DNSSEC, which is f-i-n-e fine)
- if there are multiple AS numbers for a $customer_prefix, then return multiple AAAA RRs, or if EDNS0 indicates client support for it, one AAAA RR and N RRs of a new type that carry only the AS numbers
- update core routers to route these prefixes based on the AS number in the address
- update edge routers to replace the sender's AS number in its address if its address is below the $well_known_prefix -- this takes care of the return path
- update internal routers to use only the $customer_prefix and the $end_entity for routing for this $well_known_prefix
- end entities should ignore the AS number when receiving packets, thus allowing multi-homing (i.e., let source and destination IPv6 addresses match ${well_known_prefix}:*:${customer_prefix}:${end_entity} for socket 5-tuples)
- for backwards compatibility end entities should map these addresses back to whatever the application used in its calls to bind() and connect() (i.e., if the app found an AAAA with the AS number filled in and used it for connect(), but the ${customer_prefix} is multi-homed, then accept packets from all those homes) (apps should make sure to use TLS / QUIC for security, naturally)
- when an end-entity sees a change in AS number for a peer's address matching a socket 5-tuple then update the peer's AS number / address in the 5-tuple -- this allows for migration and better path finding
I think something like this could be deployed with relatively little effort.
I have met zero network engineers who wanted to put IP version 6 in their network. It causes all sorts of problems and presents all sorts of security risks without much benefit other than the obvious one. In the data center, NAT is a feature, not a bug.
Instead, they provision IPv6-enabled load balancers and pass traffic back to load bearing servers using ipv4 instead.
It's a classic example of "this is the next best thing everyone should use it" which achieves some adoption but it's not really the next best thing. It's not the be all end all it purports to be.
We should just admit to ourselves that we need one kind of ip stack in some situations and another in another.
NAT and American assymmetric bandwidth ISPs both killed this business model and now we are stuck with tech monopolies like Cloudflare. I see this ipv4-only strategy as another monopoly tactic to kill competition.
And in Asia, it is getting more difficult not to get stuffed behind a double NAT (CGNAT), which means you can't even play games without using big-brother rent-seeker services (no port-forwarding/upnp). But at least here you get ipv6 for free and everything just works.
Also it acts as a nice security perimeter. If all IoT devices in a home were exposed to internet, It would be absolute mess.
NAT is about dealing with address space shortages, not security.
And huge % of SOHO routers won't even allow configuring IPv6 firewall which makes security a disaster.
Half of the Internet is using v6. If a lack of firewall was as common or as dangerous as people think, the supposed security disaster would have already happened. It hasn't.
Only if the ISP does no egress filtering. Most mobile carriers I’ve used deny inbound connections.
(Also, why the fsck would I want to have an ISP that does that?)
The only reason those networks aren't exposed to the whole Internet on v4 is because they're using RFC1918, not because of NAT -- but that still leaves them exposed to some outside networks, so routers come with firewalls, which act as an actual security boundary.
And they won't be exposed on v6, because those exact same firewalls work their magic on v6 too.
NAT doesn't provide and isn't needed for security. Its main security contribution is to confuse people about how secure their network is.
IPv6 (without any NAT) means that the source and destination are fully routable.
How folks DON'T see this as a functional component of security is beyond me.
However, NAT in the real world doesn't work the way you're describing here. My position is based on how NAT actually behaves, not on incorrect descriptions of how it behaves.
Or perhaps you could explain how NAT stops inbound connectivity at the NAT edge? I've tested and it doesn't, so I don't think it's possible to explain how it does, but I'm open to being wrong on that if anybody could actually explain it in a way that doesn't contract actual observed behavior.
The situation is simply that except in the rarest of cases, you're not going to be able to manipulate routing to achieve getting a packet with a RFC1918 (let's be real here, this is what we're talking about 99.9% of the time) destination address to go anywhere, much less to the target. Or more broadly, getting a packet addressed for a target behind a NAT to route TO a NAT gateway. Not to mention that if somehow it did get through, return packets are almost guaranteed to end up NAT'd, preventing traffic flow. So there's that.
On the Internet, even if your ISP didn't drop your packets outright, the routers wouldn't have the faintest idea how to route your packets to your victim.
Not Internet? Ok, let's say you're on a corporate network. You're a user and not a network admin.
Your company has a VPN to a partner company, and you're both using various subnets in 10/8. The partner has provided 192.168.1.0/24 of 1:1 NAT addresses so your two companies can share data, etc.
But there is no route in the IGP to the partner company's 10/8 network, only a block of 192.168.1.x addresses, none of which you are able to use. A magic fairy tells you that partner's payroll server has admin/admin credentials at 10.5.5.5. How are you going to get across the VPN to that address?
You won't, because you can't. Because there's no route, and in the case of a VPN, the interesting traffic probably doesn't include that IP even if you got a packet that far.
It's all simply a question of routing. Whether your traffic is being dropped by a firewall or dropped by a router, it's still being dropped.
FWIW I was a network engineer and architect at a massive enterprise for almost 15 years, and my team had management over all our Internet circuits, NAT, our WAN, etc. At the time I left we probably had >200k 1:1 NAT addresses; mostly across B2B links for management access of our devices on customer premises. It was an enormous PITA.
You can't trust an attacker to politely not send you packets that you think they can't send you. They can run `ip route add 10.5.5.5 dev vpn`/`via <next-hop>` just fine if they happen to be in the right place to do it, and your NAT won't help you.
The reason the packets are being dropped does matter. The issue at hand is all the people thinking that v6 is insecure because NAT is a security barrier; they're wrong, because it's not a security barrier, and if they continue to misattribute their security to it then they're going to keep reaching the wrong conclusions about v6.
Yes and no. The effect is the same; packets are dropped. If you have no path to a target and no way to create one, it's a security barrier.
> Neither of these things are NAT!
You're right. They're a *result* of having a NAT boundary.
> They can run `ip route add 10.5.5.5 dev vpn`/`via <next-hop>` just fine if they happen to be in the right place to do it, and your NAT won't help you.
'If they happen to be in the right place to do it' is doing a LOT of heavy lifting here. You'd have to have root access on a compromised host, e.g., a linux system, immediately adjacent to the router/firewall/VPN doing NAT. And boy would that be a stupid design for an enterprise, and it would never happen at the Internet edge. So we're talking about the edgiest of edge case unicorns.
Even if you had all that go right, return packets are going to be addressed wrong (NAT) so you'd have to figure out how to deal with that.
Your stance seems to boil down to security being an active security measure - e.g. packet filter policy. My stance is that NAT and the reality of network design naturally results in preventing unwanted traffic flows, effectively producing the same result.
I'm not saying firewalls aren't critical, just that NAT does create a barrier, and v6 advocates always blare on that it doesn't.
What makes them a pain to block? Angry users or some central database that lists these addresses as "do not block"?
Not wanting to cut off access to your users from, for example, every AT&T device (and their MVNOs).
Ofcourse legacy compatibility trumps all, along with the ubiquity of NATs and roaming and we're now just in the sunk-cost phase, being left saddled with a horribly bloated protocol (128-bit addresses was a marketing choice; not engineering) that solves no problems.
Internet engineers pre-2000 had some idealistic, heavly mathematically proven ideas that still seem revolutionary today. Due to human nature, not everything got through, but IPv6 is the best of what we have and creating another standard would be XKCD 927.
Under every IPv6 discussion people all of sudden have the urge to manually assign numbers, need to remember their cousin's phone IP and MAC address, forget firewalls exists, argue that ISP fiddling with TCP+UDP selling it as "Internet" is a good thing or that "sender" field on the envelope is a huge privacy issue.
(This is of course an incomplete and poorly thought out proposal, you don't need to dogpile me about that.)
[1] - https://nlnetlabs.nl/downloads/publications/ipv6/v6rootglue....
> but IPv6 is better
It doesn't solve any life-changing problem.
IPv4 really only had 3 problems that anybody cared about:
1. Address space size;
2. Roaming; and
3. Reliable connectionless delivery; and
4. The problems created by the at most once delivery under TCP when what we really needed was at least once delivery in many, many cases.
Even the address space size problem is less of an issue than originally predicted because of improvements in NAT, up to and including cgNAT for cellular network providers (which also somewhat addressed (2) in a limited way).
Interestingly, some of the larger companies have networks simply too large for the 10.0.0.0/8 address space.
By "roaming" I mean maintaining a consistent connection while moving between networks.
(4) has kinda fallen on QUIC (now HTTP3) but this should really be core TCP/IP Layer 3.
You could also say that TCP congestion control is pretty outdated. It's not surprising. It was designed at a time before megabit (let alone gigabit) networks. And, more importantly, latency kills throughput. Some efforts have been made on this, such as Google's BBR [2], but other problems remain like MTU windows being too small for modern networks.
So what did IPv6 do? It only solved one problem, address space, and it did it in a way that kinda created new problems. First, the address space is too large (128 bits) and the last 64 bits are kinda reserved for the job that a 16 port used to do. And why was that? Originally, it was intended that the lower 64 bits were derived from a 48 bit MAC address (as used by Ethernet and later Wifi) but they realized this was a huge privacy problem so it never happened.
[1]: https://en.wikipedia.org/wiki/Second-system_effect
[2]: https://github.com/google/bbr
[2]: https://community.cisco.com/t5/networking-knowledge-base/und...
(a while ago I needed to contact support to get an IPv6 allocation at home, but that was a very quick interaction at the time)
As if IPv6 doesn’t require a full rewrite too. So basically, no there’s no reason. They just wanted to be edgy and use hexadecimal and they’ve ruined everything.
"edgy"? Come on.
And if they used decimal I bet the complaints they didn't use hex would be just as loud and just as certain, since an IP address in dotted decimal is 50% longer than in hex.
On top of that, hex would make IPv4 a lot easier to use because of how subnets get optimized. Instead of constantly rounding to weird multiples of 8 or 16 or 32 you'd only have to deal with one hex digit at a time. And in most deployments you could skip the address math entirely by sizing your subnets 4 bits at a time: /16, /20, /24, /28.
NAT64 works much better for 6->4 connection scenarios than vice versa, but 4->6 with specific connection pairs and careful split DNS is possible.
While IPv6 doesn’t make establishing a P2P connection trivial (there are still firewalls to contend with) - it does simplify things dramatically. And as someone who is behind CGNAT, I am very grateful for the existence of IPv6.
And it is consumer devices (and IoT devices) which are the most numerous and also the most price sensitive, and this is where IPv4 is disappearing first.
I don't have anything against it per-say but I have no reason to use it either.
We just take the sheer amount of engineering that went to designing network protocols for granted.
I'm reminded of way back in the day when they wanted charge per user or per device in households.
Having said that I still want to have a router with routing rules and firewalls and a network range I can divide into separate protected networks but in reality your home ISP will most likely give you a router with a /64 address.
I'd expect "Give home users a /60 via DHCPv6-PD" to be considered "best current practice" in the ISP "community"... so if I switched to another ISP that claimed to provide IPv6 addresses, "ask for a PD-assigned /60" would be the first thing I'd try.
Breaks NAT privacy and the extensions do not do enough.
Top down pushed solution NOBODY WANTS.
Even if ipv6 was just as simple , the cost of rebuild , retest and re-deploy is enough of a barrier against migration
Your L6 code should work perfectly fine if you wrote it properly in the first place. If you pass "localhost" to getaddrinfo() with flags=AI_PASSIVE, it returns a list of socket addresses to listen on, and all you need to do is pass those to socket(). You don't need to look inside the sockaddrs and they might as well be opaque data to you, so it doesn't matter what L3 protocol they represent.
20 years ago, getaddrinfo() was 7 years old. You should have been using it already by then.
However, extrapolation suggests the 50% mark might have finally been crossed around year end.
And it will not be, as long as
* (S|D)NAT are not first class citizen in IPV6 Standards and Implementation * there's no mapping of the IPv4 Adresspace into the v6 space, so people can reroute stuff which is needed.
because only then, we can a) migrate b) rebuild the same structures.
because people will never let go of something.
Yeah, I mostly agree... IMO, a ULA (equivalent to RFC1918, so 192.168.x.x and so forth) is the only sane way to set up your IPv6 network at home, unless you're one of the wizards who owns their own prefix. Dynamic prefix delegation just breaks too many things when the prefix changes, and I really wish NPTv6 was more supported and ubiquitous, because it solves the problem in the most elegant way IMO.
> there's no mapping of the IPv4 Adresspace into the v6 space
Uh, what? What do you think ::ffff:1.2.3.4 is?
https://datatracker.ietf.org/doc/html/rfc4291#section-2.5.5....
I'd say this is actually elegant, compared to NPTv6 which is a kludge and will break things (and isn't well-supported anyway).
For the most part it works today, if I stick to using ULA’s only in my zone file, and configure hosts to prefer the DHCPv6-provided ULA for connections in the ULA subnet, it’s fine. But suddenly if you connect to somehost.local instead of somehost.fqdn, the machine picks a GUA source address and you’re back to being unpredictable.
So although I say I want to use NPTv6 and be ULA-only, I don’t actually do that today, so I’m not super familiar with the downsides to the approach. But it does sound a lot cleaner to me in theory.
> if you're only using it for outbound connections then it changing isn't going to break anything.
A prefix change absolutely does break things in a lot of setups though. It happens something like:
- Your router reboots unexpectedly (no time to rescind the RA)
- Router comes up and gets a new prefix, starts advertising it
- Clients are brain dead and continue using the old prefix when making outbound connections.
I’ve had this happen and both Apple devices and Linux devices (I had no Windows machines) kept using the old prefix until I went around and rebooted them. So connecting to any IPv6 WAN address would fail, and only IPv4 was saving me from my internet being down until I went and manually rebooted everything.
There have since been RFC’s that come up with recommendations for routers to keep a stateful log of old prefixes, so that they can rescind them (advertise a zero TTL) when a new prefix arrives… but afaict none of them actually do this.
now applications (including DNS/NAT) have to support it
i also forgot something (but not against your comment):
* there needs to be guidelines how applications should differentiate between used ipadresses (link, site, global and so on)
systemd is part of Linux Distros?
And systemd is part of some Linux distros, yes. But not all. And Linux, the kernel, is agnostic towards IPv4 vs. IPv6 as far as I know.
So saying "Linux prefers IPv4 DNS" and linking to a github issue about "resolved" doesn't make much sense.
Even more than IPv4, not knowing enough about IPv6 can introduce a lot of unintended issue, consequence and even security gaps in your assumptions.
Maybe there was an IPv7 or 8 that will be more palatable.
If I need to connect to my home Fedora machine from work, a simple "ssh fed.nono.io" works just fine — I don't need to activate my Wireguard VPN; I don't need to worry about address space collisions.
Vs. real meat is in the comments on the Register's site.
I don't think there is any way it could have been.
Apple TV, Amazon Echo/eero, Google Nest are all Thread/Matter hub.
Ikea just started to selling cheap Thread devices. It will soon be mainstream to have IPv6 devices in your home network.
::ffff:192.168.1.1 == 192.168.1.1 (as far as the linux kernel is concerned, in most contexts)
I've been using IPv6 via Starlink for months now and it was a big ho-hum when I deployed it. It just works.
I'm sure someone will fuck this up for us, but IPv6 should at least in theory enable us to be rid of NAT. Anyone who has ever done NAT traversal for peer discovery is having wet dreams about that future!
Sure NAT traversal for peer discovery doesn’t sound pleasant, but routing issues that no one understands or care about is worse.
We all thought the internet would become decentralized and that everyone should have an IP and a funky website. But instead social media took over, big tech and a few big discussion sites where we all must fit in a digital life and watch ads and share our data to become a good product for all the others to consume.
I have ONE static external IPv4 for my network.
I can handle everything I want with it. And block everything I dont want my network to be.
So I just disable IPv6 on router (Mikrotik).
Not interested, not wanting it. That is it. If someone needs it, feel free to use it. I wont support double configurations on my router because of it.
Then it's failure is by design. I should not want to multiplex/bridge different versions of the network-layer protocol; and certainly not to avoid using the new protocol because the old one seems more usable and approachable.
But attempts at providing replacement were stymied - IETF went not-invented-here finally getting v6, while USGOV went with CLNS, and meanwhile vendors hemmed and hewed to avoid spending any money on actually implementing changes and then allowed NAT availability to crush arguments and mandates.
Legacy IPv4 would be trivial to support via NAT, and we wouldn't have to deal with address shortages either globally or locally. I'm sure every sysadmin/cloud person dealt with having to arrange subnets by hand, or the fallout when you just ran out of addresses and had to tear down multiple layers of routing just to make more address space.
Computers default to 64 bit integers, I don't see why this couldn't be done on the network.
The amount of work doesn't depend on the number of bits either, so adding fewer bits is a false economy. Deploying a new version of IP is so hard that you only want to be doing it once, not once every time you need an extra few bits.
> Outbound IP addresses
> Fly Machines have IPv6 addresses from which they make requests to the wider internet without going through the Fly Proxy.
It's sort of interesting dude says Security and Plug-and-Play weren't available in v6 since SLAAC and IPSec are mandatory parts of the spec. But sure, AH and ESP options are never as simple as they should have been and it's not impossible to pick options for your organization that don't match what a remote organization supports. I still prefer it to the crap-shoot that is TLS ChangeCipherSpec. (Though 1.2 and 1.3 aren't as bad as the old days.)
Contrary to the narrative about your parents not being able to cope with anything technical, my mom was able to configure her mac to speak to the family VPN with no problem. Of course, my mom taught me code in Lisp in the 70s and used a Sun 3/60 as her daily driver in the late 80s, so maybe that's not the best example.
Sure. V6 didn't take over the world, but neither did SNA or IPX/SPX, though I would argue v6 is MUCH more common these days than either IBM or Novell protocols. V6 is used in the corner of the internet by people who want to use V6. Maybe there's a "those who know don't tell, those who tell don't know" narrative here. I've sort of stopped evangelizing. If the main thing you worry about is watching Netflix, MMORPGing and commenting on Reddit, you don't need V6 and it does require a different bit of knowledge than setting up V4.
#OldManYellsAtClouds
I used to be a network admin, so I know how to configure networks. IPv6 zealots accuse me of incorrect config, doing it wrong, etc. Maybe that is the case, but if I, a sophisticated user, can't get it working well, what chance does a non-technical person have?
My assumption is they just deal with the issues and chalk it up to "technology sucks". But I know better. I've experienced the internet when it works, and I know when it isn't working right.
I think IPv6 is better in theory, and I look forward to the day that it is in practice. But today is not that day.
You'll encounter the same problem on v4, where it's just as difficult to fix as it is on v6. Why single out the latter?
IPv4 "works" and ISPs are incredibly resistant to changing things that "work".
Because support is needed basically end to end, it's going to take an ungodly amount of time for ISPs to figure this stuff out.
It's pretty frustrating having all my hardware support v6 with the only barrier being my ISP who refuses to support it in my location (they support it in other locations).
Except for people. Specifically, wireline end users. Triply so if they're on Fiber.
ex: T-Mobile fiber rollout is IPv4-only and CGNAT.
>>> America has one of the highest IPv6 adoptions in the world.
>> Except for people. Specifically, wireline end users.
Triply so if they're on Fiber.
> I don't think so?
The rest of them are effectively IPv6-Never-Evers. Our 1 cable ISP (spectrum) offers it. None of our fiber providers do (Frontier, WideOpenWest, T-Mobile, Optyx, Evolution). Given how new fiber deployments seem to be IPv6-adverse, I wouldn't be surprised to see a bit of contraction over the next year or so.
I've posted elsewhere here that I'd relentlessly bugged my provider to deploy their IPv6. They have a /40 allocated. Or had. They just ditched it. Which I guess was their way of telling me to stop asking.
¹ https://www.google.com/intl/en/ipv6/statistics.html#tab=per-...
When I queried DNS for IPv4-only sites, I got IPv4 and IPv6 addresses. As recently as last month, I would get an empty result for those same queries (no IPs at all).
After 2 years of off/on attempts, T-Mobile IPv6 is (for the first time) working for me as you describe.
------------------------------------------------------------
> Are you trying to VPN directly to IP addresses instead of DNS names?
DNS resolved hostnames
> it's just that you need to translate the IPv4 addresses into their corresponding NAT64 IPv6 address (which is usually done for you by the T-Mobile DNS server)
[ed:Below is from memory, based on last month's results. It's from memory because when I 1st tested today, my hotspot gave me IPv4 (a thing it does ~30% of the time)]
TMobile's DNS servers give me an empty response to IPv4-only hostnames. When I'm in IPv6 only, there are a lot of sites I can't reach.
The response is appreciated.
https://en.wikipedia.org/wiki/IPv4#Header https://en.wikipedia.org/wiki/Internet_Protocol_Options https://en.wikipedia.org/wiki/IPv4#/media/File:IPv4_Packet-e...
Similarly, we have 30 years of experience that vendors will happily break optional headers or flags.
I'm no expert on IPv4 or IPv6, but if they had designed IPv6 to be able to route fine to IPv4, we'd be OK.
It would at least give people an upgrade path where their old stuff that couldn't be patched / updated and were stuck on IPv4 could be slowly killed off in the path of least resistance down the dependency line.
This 'dual stack' approach doubled up on everything up front and meant we all had to do both during the transition (which has taken 30 years).
That still requires that if you have used BSD Sockets before getaddrinfo was added (or like many, didn't learn about it for years) then you had to rewrite the parts of your application that are responsible for handling connections.
So the very thing you're advocating for exists
And I work with IP networks all the time, as well as run LAN Parties as a business. You'd think I would have encountered at least ONE reason to give a crap about IPv6 by now.
But nope, not one reason.
IPv4 gets work done. IPv6 is just a topic that we can wax poetic about, but nothing else.
The network my desktop is on doesn't use v4. It works. v4 isn't a required dependency.
$ wget https://github.com/
Resolving github.com (github.com)... 64:ff9b::8c52:7204, 140.82.114.4
Connecting to github.com (github.com)|64:ff9b::8c52:7204|:443... connected.
HTTP request sent, awaiting response... 200 OK
$ wgetnull 'https://news.ycombinator.com/
Resolving news.ycombinator.com (news.ycombinator.com)... 2606:7100:1:67::26, 209.216.230.207
Connecting to news.ycombinator.com (news.ycombinator.com)|2606:7100:1:67::26|:443... connected.
HTTP request sent, awaiting response... 200 OK
Because there's such an incredible amount of v6 addresses. You could pay a trillion dollars per second for a /64 and still only pay $1.70/year for each address.
> Why is IPv4 the incumbent 30 years after IPv6?
Because IPv4 was the only choice until IPv6, and replacing the Internet's L3 protocol is hard and takes a long time.
PSA that news.ycombinator.com is 2606:7100:1:67::26 now.
That is all. Except for the part where it doesn't help us on IPv6-Never ISPs.
Half. The. Internet.
What a failure. /s
I wouldn't say so. Some mobile carriers and big data centers have used IPv6 to pretty much completely solve the problem of being able to assign a unique address to devices.
For mobile devices, moving 50% of traffic over to IPv6 means buying half as many CGNAT/v6-to-v4 boxes (of various kinds).
And on the v6-inside, unique address can be assigned. Legal requirement and court orders suck when you get "who had A.A.A.A:32800 at time T?" if you have to go through three levels of NAT to decode that. So even if a customer only accesses IPv4, having their actual handset only be assigned IPv6 makes things easier and cheaper. Even if they share an outside address, there's only one translation so the inside is unique.
For big data companies, it means not needing to solve the problem of running out of 10/8 (yes I'm aware of the other private addresses), and having an address plan problem any time they make an acquisition.
And I've seen large providers who build their whole actual network with IPv6, and only tunnel IPv4 on top of it. Huge savings in complexity and cost of IPv4 addresses.
So what I'm saying is that I've seen first hand in multiple large providers of different kinds how IPv6 is delivering incremental payoff for incremental adoption.
It doesn't have to be 100% before we get ROI.
> it is not a success.
About half of even public traffic on the most complex and distributed system ever built is IPv6.
It's going slower than I'd like, but it's definitely paying off.
There are still ATM and X.25 networks out there, so is IPv4 a failure? (admittedly, a bit hyperbolic)
I'm working on a problem right now at a large company to move a thing from IPv4 to IPv6 because the existing IPv4 solution is running out of addresses, and it's impossible (for multiple reasons) to "just add more IPv4". Can't go into details, sorry.
Well I addressed that too, so…
> private networking
To some extent this is a distinction without a difference. Again, as I said…
> we would probably be having this very discussion on an IPv6 enabled site
$ host news.ycombinator.com
news.ycombinator.com has address 209.216.230.207
news.ycombinator.com has IPv6 address 2606:7100:1:67::26
> v6 [is] a second class citizen
It is. Except for endpoints (again) as I mentioned…
> the cost difference between a v4 address
The alternative to buying v4 is not just private addresses, as (again, as I was very specific about) private v4 addresses also have a cost.
v4 is priced according to the demand. Without IPv6 demand would be much higher, as the alternative (with CGNAT and intra org problems) would drive up the demand for more public addresses.
To say that "the cost should be equal" for IPv6 to not be a partial/in progress success misses the entire economics of addresses.
The biggest most complex system in the world shuffles half its traffic on IPv6, and rising, with million of devices without any form of IPv4 address.
So no, I would not say it's a failure.
Most mobile devices are only issued an IPv6 address and therefore when the masses do google searches it uses IPv6 and makes it look like there is huge adoption.
You seem to be asserting that dual-stack machines use IPv4 by default, but that's not really true. If your machine has both IPv4 and IPv6 connectivity, browsers will in fact use IPv6 to connect to sites that support it, like Google. They prefer IPv6 by default and fall back to IPv4 if IPv6 is slower (Happy Eyeballs algorithm).
Of course, random software can mostly use whichever it wants, so I'm not claiming every process on such a machine will use IPv6, but most common stuff does.
Not saying its like that everywhere, but Im not seeing IPv6 default usage on dual stack systems in my experience.
If you're on a Linux machine, check `ip -c addr show` for an address that's "scope global" and doesn't start with "f". Those are the ones you need. If you have one of those, check `getent ahosts google.com` to see if v6 is being sorted before v4 in DNS lookups, and then `wget google.com` to see if wget prints any errors connecting to the v6 address.
If you have GUA addresses and nothing is outright broken, devices and software that support v6 will prefer it over v6.
You are simply misinformed. Either your setup doesn’t actually support IPv6 (or it’s much slower than IPv4 due to something being misconfigured), or you turned it off at some point, or you’re making a mistake in how you measure it. Because IPv6 is used by default on systems that support it. You don’t have to take my word for this, you can google it or ask someone else to try it.
So that measures everybody who has working IPv6. https://www.google.com/intl/en/ipv6/statistics.html
To me the specifically does not say, “could you” reach the servers but “did you”.
Because of Happy Eyeballs if you measure whether your users did use IPv6 you don't find out whether they could have done so, and so your results will be thrown off by happenstance.
I don't understand your logic. How does a large amount of devices using IPv6 to connect to IPv6 servers only "make it look" like there is IPv6 adoption but somehow it shouldn't count?
Most other large eyeball networks have as well.
There’s no way in which IPv6 is less private than IPv4. An ISP issues your house an IPv4 address and an IPv6 /48 network. Both of those can be subpoenaed equally. The privacy extensions work as advertised.
And in reality land, the big companies are the ones pushing for the upgrade because they’re the ones hardest hit by IPv4’s inherent limitations and increasing costs. Same rando in Tampa isn’t leading the charge because it doesn’t affect them much either way.
With IPv4 behind CGNAT you share an address with hundreds of other users. This won't protect you against a targeted subpoena, but tracking companies typically don't have this kind of power, so they have to resort to other fingerprinting options.
On the other hand, an IPv6 address is effectively a unique, and somewhat persistent, tracking ID, 48/56/64-bit long (ISP dependent), concatenated with some random garbage. And of course every advertiser, every tracking company and their dog know which part is random garbage; you are not going to fool anyone by rotating it with privacy extensions.
For tracking purposes, an IPv6 address is 48 bits long. That’s what identifies a customer premise router, exactly like a IPv4 /32 identifies one. The remaining 80 random bits might as well be treated like longer source port numbers: they identify one particular connection but aren’t persistent and can’t map back to a particular device behind that router afterward.
For some reason, "CGNAT == privacy" is a very common sentiment on Hacker News. Yeah, Hacker News. It's bewildering, and after my last comment [0] talking about it, I have kinda already given up trying to convince people that CGNAT is devilish and not at all a privacy protector.
With NAT, an adversary can't send my computer any packets either unless I explicitly set up port mappings.
So, if you can't send my computer any packets, how is it not providing security?
Of course, it doesn't provide full security like a firewall can do, since there's ways to punch holes in the NAT from the inside. But it seems just as incorrect to fully dismiss "NAT == security".
NAT provides some functional security. It is not a replacement for a proper firewall.
Because if those nice IoT devices were reachable from the internet they could be compromised easily due to their likely shitty firmware with backdoors and hardcoded passwords.
> Trusting on NAT alone is idiotic and foolish.
Sure, but that's a far cry from saying NAT provides no security.
Perhaps this is the difference, some people are concerned with being anonymous from companies like google, amazon, etc. Some don't mind that, as long as they are anonymous from a government.
Your mention of subpoena suggests you don't care about google tracking you.
Some public evidence: https://www.alphabetworkersunion.org/press/google-lays-off-c...
The people I want to protect my privacy from are google, facebook, amazon, they can't subpoena my IP, they can track me just fine though.
The tracking is a moot point. You can be tracked using the same technologies whether you connect though v4 or v6, and neither stack has the advantage there.
It, um. No, it doesn't do that. You can use proxies and VPNs in v6, and you're about as trackable by IP as you are on v4.
Either you use address translation or you don't.
VPNs as a youtube sold service. Mullvad/mozillavpn for one
I get an IP of fc00:bbbb:bbbb:bb01::1 and it uses NAT66 to place me in New York despite being in the UK
1.|-- fc00:bbbb:bbbb:bb01::1 0.0% 10 78.6 80.2 78.6 82.0 1.2
2.|-- 2607:9000:a000:34::1 0.0% 10 80.1 80.3 79.3 81.2 0.7
3.|-- ??? 100.0 10 0.0 0.0 0.0 0.0 0.0
4.|-- 2607:f740:70:101::1 0.0% 10 82.2 83.9 79.8 104.3 7.2
5.|-- 2001:550:2:d::4a:1 90.0% 10 80.1 80.1 80.1 80.1 0.0
6.|-- be3448.agr22.jfk02.atlas.cogentco.com (2001:550:0:1000::9a36:1a9) 60.0% 10 80.4 81.0 79.2 82.9 1.5
And no, proxies were either never obsoleted or they were obsoleted by routing. Nothing to do with v6.
I’m aka unsure if IPv4 really gets you the privacy advantages you think it does. Your IP address is a data point, but the contents of your TCP/HTTP traffic, your browser JS runtime, and your ISP are typically the more reliable ways to identify you individually.
The downvotes are because you’re needlessly combative, preemptively complaining about downvotes.
Realistically though there's enough fingerprinting in browsers to track you regardless of your public IP and whether it's shared between every device in the house or if you dole out a routable ipv4 to every device.
CG-NAT gives more privacy benefits as you have more devices behind the same IP, but the other means of tracking still tend to work.
For me I just don't see the appeal of supporting both ipv4 and ipv6. It means a larger attack surface. Every year or two I move onto my ipv6 vlan and last a few hours before something doesn't work. I still don't see any benefit to me, the user.
Yes, browser fingerprinting is a big issue, but it can be mitigated. The first thing everyone should do is to use a network-wide DNS blacklist against all known trackers (e.g. https://github.com/hagezi/dns-blocklists) and run uBlock Origin in the browser.
You can go further and restrict third party scripts in uBlock, or even all scripts. This will break at lot of websites, but it is a surefire way to prevent fingerprinting.
Then of course there is Tor.
This one was particularly scary: https://malwaretech.com/2024/08/exploiting-CVE-2024-38063.ht...
Sigh...
Yep. For the OP, IPv6 "Privacy" addresses do what he's looking for. You can change how long they're valid for on Linux, so you can churn through them very frequently if you wish.
> Every year or two I move onto my ipv6 vlan and last a few hours before something doesn't work.
Odd. I've been using IPv6 for like fifteen, twenty years now with no trouble at all. If you've been using a "single stack" IPv6-only network, well, there's your problem.
> For me I just don't see the appeal of supporting both ipv4 and ipv6. It means a larger attack surface.
The attack surface with IPv6 is exactly as large as if each of your LAN hosts had a globally-routable IPv4 address. Thinking otherwise is as smart as thinking that the attack surface on a host increases linearly with the number of autoconfigured IPv6 addresses assigned to that host from the same subnet.
If you don't want the IPv6 hosts on your LAN to be reachable by unsolicited traffic, set the default policy for your router's ip6tables FORWARD chain to DROP, and ACCEPT forwarded packets for ESTABLISHED or RELATED connections. If you're not using ip6tables, do whatever is the equivalent in the firewall software you're using. If you know that you have rules in your FORWARD chain that this change would break, then you already knew that you could simply drop unsolicited traffic in the FORWARD chain.
Unrelated to that, I see no reason to get rid of IPv4.
I expect that the future will be that nearly all "residental" [0] and non-datacenter business connections provide globally-routable IPv6 service and provide IPv4 via CGNAT, as IPv6 will be used for servers deployed at these sorts of sites. [1] I expect that the future will be that all datacenters and "clouds" will provide globally-routable IPv6 to servers and VMs, and globally-routable IPv4 to the same by way of load balancers.
So, home servers [1] will use IPv6, datacenter and "cloud" servers will use IPv4 and IPv6, and "legacy" devices that work fine but will never have their IP software updated will use IPv4.
I see IPv6 as a "reduce the pressure on the IPv4 address pool" mechanism, rather than a "replace IPv4" system. Again, I see no reason to get rid of "short" IP addresses. Default to using "long" ones, and keep the "short" ones around just in case.
[0] I'm including people's personal mobile computers in this definition of "residential".
[1] "Servers" here include things like "listen" video game servers or short-lived servers for file transfers and stuff like that.
"IPv6 just turned 30" - literally the first part of the post title.
The rest of the post is equally baffling, you are just clinging to a legacy bottleneck (NAT) that was never designed to be a security feature
It's virtually always used with some firewall rules, so it sort of is? It's just dogma to insist that there are no security benefits to having a single choke point for traffic.
NAT also include many-to-many and one-to-one translations, and those are just as easily implemented in anything routing with no extra memory and complexity required. This is sometimes referred to as symmetric NAT.
The firewall rules are what is providing the protection, by applying a policy that traffic must be initiated by a host on the "more trusted" network or whatever your prefered terminology is. That can happen without NAT and does all the time. Techniques for forcing translations have been well known as long as NAT, and there are probably some unobvious ones out there too. In the 1990s it was still common to get multiple IPv4 addresses if you went to the trouble of having ISDN or whatever, and they were equally protected by a firewall that did not do NAT.
Take a look at the IPv6 Google graph that everyone loves so much:
https://www.google.com/intl/en/ipv6/statistics.html
You can clearly see an initial steep spike to the curve where mobile adoption was new and fierce, and then the curve starts slowly becoming less steep over the last 10 years. It will peter out and remain steady when mobile device adoption reaches critical mass.
Mobile and Telco ISPs are the only ones not issueing IPv4 addresses to their clients and this will never change.
Saying NAT 'Won Out' may have been a bit of a flippant overreacting statement which I apologise for, but IPv6 will never replace IPv4 outside of the mobile space and that was my core point I was (poorly) trying to make.
You mean the single largest increase in deployed computing devices in the history of computing and fastest growing type of deployment in the developing world? That mobile device space?
It’s amazing to me that you’ve spent hours arguing this point on this thread, when it‘s based on an assumption (dual-stack machines use v4 by default) that is simply, verifiably wrong. If that were true, then you’d be right that nearly all IPv6 usage is attributable to mobile. But it’s not true!
to protect your privacy
"Ah, crap, avahi isn't working, but fortunately I remember that that computer is blablabla.34." The IPv6 equivalent of that is like "fd12:3456:7891::1". Absolute non-starter.
A large number of my devices and websites I visit use IPv6. Its success has highlighted the fact that I don't want it. Just today I disabled IPv6 on my router because I suspect it as a vector for tracking.
IPv6 offers nothing of value to the user. It might as well be shelved forever.
ISPs do not want this.
That is all you need to know about why you can’t have IPv6.
“ Those who cannot remember the past are condemned to repeat it”
{kind=link}
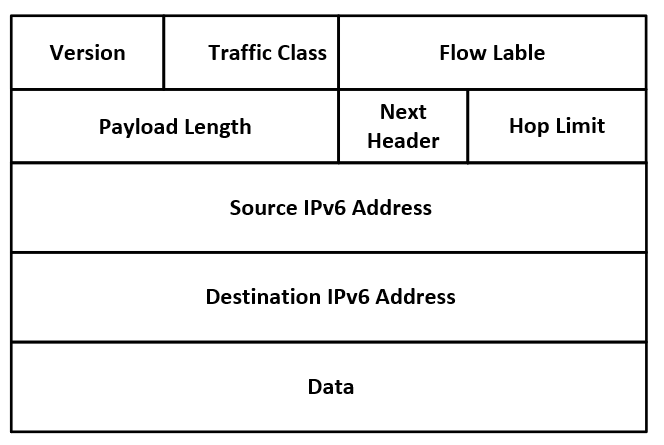{kind=link}
{kind=link}