with movieIds as (select id from Movie where title = $1),
actorIds as (select Actor.id from Actor join ActorMovie on [...]
where ActorMovie.Movie in movieId),
alsoActedIn as (select id from ActorMovie where actor in actorId),
movieResults as (select * from Movie where id in movieIds),
actorResults as (select * from Actor where id in actorIds),
alsoActedInResults as (select * from Movie join ActorMovie on [...]
where ActorMovie.id in alsoActedIn)
select * from movieResults
full outer join actorResults on false
full outer join alsoActedInResults on false;
MovieId,MovieTitle,ActorId,ActorName,MovieId,MovieTitle,ActorMovie.actor
0,"Indiana Jones",null,null,null,null,null
null,null,0,"Harrison Ford",null,null,null
null,null,null,null,0,"Indiana Jones",0
null,null,null,null,1,"Star Wars",0
null,null,null,null,2,"The Fugitive",0
[{
id: 0,
title: "Indiana Jones",
actors: [{
id: 0,
name: "Harrison Ford",
alsoActedIn: [
{id: 1, title: "Star Wars"},
{id: 2, title: "The Fugitive"},
]
}]
}]
This pattern has saved me from some truly awful query logic.
What order of magnitude do you use this on and find it acceptable? 1MB, 1GB, 1TB, 1PB? At 1GB it seems okay. At 10GB things aren't great, at 100 GB things are pretty grim, and at 1TB I have to denormalize the database or it's all broken (practically).
I'm not a database expert, but I don't feel like I'm asking hard questions, but I'm running into trouble with something I thought was 'easy', and matches what you're describing.
select Movie {
title,
actors: {
name,
alsoActedIn := (
.movies { title }
filter .id != Movie.id
),
},
} filter .title = <str>$title;The result in your example looks exactly like JSON. Am I missing something?
Also, what is the point of avoiding JSON? Your client has to unmarshal the result either way.
It's worth avoiding json on the wire if possible, because the extra layer of encoding will complicate things. Any good postgres integration will know how to safely deserialize and discriminate between (e.g.) DateTime and DateTimeWithTimeZone. But with json, everything's stringified.
I'd expect to talk about anything in a DB as "structured data". Flexible serialization formats such as JSON or XML are "semi-structured". And something from e.g., an office document is "unstructured".
This is not a complaint or criticism. I understand the article just fine. It's just interesting how different perspectives can affect what words mean (:
[1] https://martin.kleppmann.com/2017/03/27/designing-data-inten...
Mark Rosewater likes to write about his personal concept of "linear" Magic: the Gathering decks, which are decks in which the cards tend to pick up synergy bonuses from each other, so that having two of them together is considerably more powerful than you'd expect from the strength of those two cards individually.
This always bothers me because it is the opposite of the more normal use of "linear" relationships, in which everything contributes exactly as much to an aggregate as it's worth individually.
SQL, as a language is clunky, true. It can be patched here are there, either by PipeSQL or by various ORMs. I agree, that it would be wonderful to have standardized tooling for generating JSON like in the post.
Yet, with relational databased you can separate concerns of: what is your data and what you want to display. If you use JSON-like way to store data, it can do the job until you want to change data or queries.
The shame, to me, is that SQL is _unnecessarily_ clunky with producing query results with nested/heirarchical data. The relational model allows for any given value (field or cell value) to be itself a relation, but SQL doesn't make it easy to express such a query or return such a value from the database (as Jamie says - often the API server has to "perform the join again" to put it in nested form, due to this limitation).
First normal form explicitly forbids nested relations though. Relational algebra does not support nested relations for this reason.
But perhaps nesting relations might make sense as the final step, just like sorting, which is not supported by the pure relational model either.
Usually, relational algebra doesn't have many restrictions about the type of the atomic values it deals with, what makes sequences and relations perfectly valid candidates.
But yeah, there are many reasons for you to normalize your data at rest.
As FOL is as powerful as HOL but easier to optimise, it has become the basis for relational databases. The trade-off is that you have to normalise your data so that you can efficiently query and apply constraints to it.
But yes, just because your data at rest should be flat relations, that doesn't mean that the results of your queries need to be flat. I think querying a well-normalised database and returning nested JSON makes a lot of sense.
The straighforward translation of a hierarchical database into relational form is to represent nested structures as nested relation. But if you cant query these nested relations the database is useless. So you either need to normalize to 1NF or extend the query language to query nested relations.
You could probably be able to promote those relations up on the hierarchy by using them in joins. But I don't think it's reasonable to mix queries of several levels. (I can't even imagine how the syntax for that would look like.)
Your new fad NoSQL may or may not be relevant tomorrow. SQL has inertia. I have no problem finding experienced SQL developers. Do there even exist experienced developers for technologies that have been invented yesterday? Will you be able to find somebody to maintain it tomorrow?
VIM has autocomplete nowadays old man! ;)
No excuse to use a language that has the syntax of "get (things...) from (thing)" and make it impossible contextually to know what the possible (things...) are until later.
> Your new fad NoSQL may or may not be relevant tomorrow.
NoSQL is a misnomer, this is exactly why the whole conversation I'd like to have is nearly impossible. SQL and relational aren't synonyms. The guys who co-opted the name NoSQL to mean "non-relational DBs" really screwed us.
It's like someone created a movement called "No-C++" and defined it to mean "we are only going to use programming languages that run in an interpreter, no bare metal!" Then someone comes along suggesting the ideas behind Rust etc. and everyone argues against it by saying "No-C++ is dumb, sometimes you need to run on the bare metal!"
That's before you even encounter the people who firmly claim that SQL and the relational model are one and the same, and there is no conceivable other way to represent it. Which I regularly do encounter here on HN.
The aggressively common pipe-delimited sproc output (the standard hack to get around commas being common in strings, instead of finding a legitimate data format) is another clear example of the brain damage the poor DBA incurs through constant investment in “modern” relational databases.
Right now the DB I'm paid to babysit provides cli tools that flip between tabular and k/v list output without making that configurable, or a tabular form that doesn't include headers, or a 3rd party tool that will, but has the spectacularly annoying "error on line 1 : multi-line query" issue. Or things that are slow or only talk via generic protocols like odbc etc etc etc
I think you're being a little unfair about the pipe delimited thing though, it's a least worst compromise based on who we're providing the data too - non technical business people, the vast majority of whom use excel or similar tools and couldn't even tell you what "data format" means, let alone configure their systems to parse something else.
Personally I had a bit of an epiphany around the ascii delimiters (us/fs/rs/gs) which work extremely well when the data is ascii/utf-8, and make data interchange between shell cli tools very easy. But they've also invisible and little business software supports them in a friendly way. Telling someone in accounts or market to "use octal 034" helps no one.
And I've resigned myself to using multiple tools, dev with tool 1 with decent error messages, tool 2 for production use because it can actually produce sane output formats.
What I don't have a choice on is which db we use, and it's not modern or cool and honest most things don't even have drivers for it
Technically it is good enough to perform the function, but at the same time it’s just soul-crushing how much quality of life is being wasted.
* Adjacency List Model
* Path Enumeration Model, also known as the Materialized Path
* Closure Table Model (or Bridge Table)
* Nested Set Model
* Recursive CTEs
Also, modern SQL is an incredibly powerful language. Good SQL can save you from lots of dumb data munging code if you know how to wield your database properly. Especially for analytical queries, but also more typical application code IMO.
And in fact, good constraints also can improve query performance. If the optimizer knows this column is unique, or that column is guaranteed to have a corresponding value in the joined table, it can do all sorts of tricks...
Something else I find confusing is that every developer seems to want every database query for a single object to return a single row with a thousand columns, and anything multi row or with multiple results is way too complicated to handle. This goes double for report writing software.
I really wonder what we're doing with database providers (drivers) that makes people want to develop ORMs when ORMs consistently feel like 10 ton gorillas. If the database world is so disparaging of the "row by excruciating row" processing, why do the drivers exclusively present data that way and no other?
I don't mind that the tables in relational databases are essentially 2d matrices. I can do the hierarchy with the joins. I just need a way to get the data out in a sane format.
Last time I brought this up ~15 years ago everyone hated on me. But everyone knows this is ultimately the data we want to get out of the system.
However, the issue is that relations are great inside the RDBMS, but they are not necessarily the best presentation of data outside the RDBMS. MS Access, as maligned as it is, has been able to display subsheets in a collapsible hierarchy [0] for decades at this point.
Really, there should be a way to tell the RDBMS to output data as hierarchies based on the join without having to jump through the, quite frankly, completely ridiculous subquery syntax bullshit that JSON and XML formatting currently requires. Even if it only works in 95 out of 100 cases; even if you have to manually tell the query somehow what the key fields are to agglomerate based on. It should be way easier than having to stitch strings together like you're still using printf() for everything at all times.
[0]: https://www.fmsinc.com/free/NewTips/Access/SubdatasheetName....
I think pushing multiple joins to what is still a relational database and getting a complex output isn't the worst idea in the world, as a higher-level layer on top of a regular database.
On the other hand, "it needs four queries/RTTs" is not the worst thing in the world. It needn't be the goal of a system to achieve theoretical minimum performance for everything.
Let those who truly have the problem in prod push the first patch.
Codd was right in that if you want transactional semantics that are both quick and flexible, you'll need to _store_ your data in normalized relations. The system of record is unwieldly otherwise.
The article is right that this idea was taken too far - queries do not need to be restricted to flat relations. In fact the application, for any given view, loves heirarchical orginization. It's my opinion that application views have more in common with analytics (OLAP) except perhaps latency requirements - they need internally consistent snapshots (and ideally the corresponding trx id) but it's the "command" in CQRS that demands the normalized OLTP database (and so long as the view can pass along the trx id as a kind of "lease" version for any causally connected user command, as in git push --force-with-lease, the two together work quite well).
This issue is of course that SQL eshews hierarchical data even in ephemeral queries. It's really unfortuante that we generate jsonb aggregates to do this instead of first-class nested relations a la Dee [1] / "third manifesto" [2]. Jamie Brandon has clearly been thinking about this a long time and I generally find myself nodding along with the conclusions, but IMO the issue is that SQL poorly expresses nested relations and this has been the root cause of object-relation impedence since (AFAICT) before either of us were born.
[1] https://github.com/ggaughan/dee [2] https://www.dcs.warwick.ac.uk/~hugh/TTM/DTATRM.pdf
The biggest mistake was thinking we could simply slap a network on top of SQL and call it a day. SQL was originally intended to run locally. You don't need fancy structures so much when the engine is beside you, where latency is low, as you can fire off hundreds of queries without thinking about it, which is how SQL was intended to be used. It is not like, when executed on the same machine, the database engine is going to be able to turn the 'flat' data into 'rich' structures any faster than you can, so there is no real benefit to it being a part of SQL itself.
But do that same thing over the network and you're quickly in for a world of hurt.
Shared as in on a single mainframe, yes. Remember, Codd was a mainframe guy — even helping to design one before starting work on the relational model. It wasn't until Oracle came along did anyone really think it would be a good idea to slap networking directly on top of SQL.
> Concurrent access and thus networking was there from the beginning.
Again, the trouble is the high latency that networks introduce. That wasn't there from the beginning. Mainframes are designed for low-latency. That is a relatively new constraint that Codd didn't need to think about...
...But we in the internet age do. The high latency means that, in many cases, we can't realistically use SQL as it was intended. Which is why we have all ended up building bespoke DMBSes that speak things like JSON instead of SQL. Granted, there have been some efforts to bring richer data structures to SQL, including JSON support, but they're all pretty hacky, frankly. More ideal would have been to design a better language for the client/server database model from the start, but we are no doubt in too deep now. Worse is better applies.
Codd was writing 10 years before the idea of transactional semantics was formulated, and transactions are in fact to a great extent a real alternative to normalization. Codd was working to make inconsistent states unrepresentable in the database, but transactions make it a viable alternative to merely avoid committing inconsistent states. And I'm not sure what you mean by "quick", but anything you could do 35 years ago in 10 milliseconds is something you can do today in 100 microseconds.
It's specifically about _fast_ transactions in the OLTP context. When talking about the 1970s (not 1990s) and tape drives, rewriting a whole nested dataset to apply what we'd call a "small patch" nowadays wasn't a 10 millisecond job - it could feasibly take 10s of seconds or minutes or hours. That a small patch to the dataset can happen almost instantly - propagated to it's containing relation, and a handful of subordinate index relations - was the real advance in OLTP DBs. (Of course this never has and never will help with "large patches" where the dataset is mostly rewritten, and this logic doesn't apply to the field of analytics).
Perhaps Codd "lucked out" here or perhaps he didn't have the modern words to describe his goal, but nonetheless I think this is why we still use flat relations as our systems of record. Analytical/OLAP systems do vary a lot more!
I think that if you're processing your transactions on tape drives, your TP isn't OL; it's offline transaction processing.
I think Codd's major goal was decoupling program structure from on-disk database structure, not improving performance. There's a lot of the history I don't know, though.
Classes/Structs know about their children.
Relations know about their parents. If you want crazier m*n relationships you use an association table.
Did the author just not know? Or he didn't see it worthy of dismissal?
> Doing this transformation by hand is tedious and error-prone. We call this tedium "the object-relational mismatch" but it isn't really about objects or relations.
It really is.
> The fundamental problem is that fitting complex relationships to human vision usually requires constructing some visual hierarchy, but different tasks require different hierarchies.
Yes. Different tasks require different hierarchies. One particular way of doing things should not baked into your 1970s relational model.
This is NOT the case with modern SQL, as it supports JSON. The typical Postgres use-case would be to produce denormalised views for the specific relationships and/or aggregates in JSON form. LATERAL, the correlated sub-query, is really convenient in avoiding double-counting. The rest of the article deals with object-mapping, which is really a poor man's VIEW. Time and time again, software engineers reinvent the data-access wheel out of ignorance to database capabilities.
[1] Actually causality is backwards here - postgres supports JSON only because the Restful API servers that frequently interact with it need to provide JSON to _their_ clients... and so it was a highly demanded feature.
My thinking is everything I could get done by the DB avoids heavier and maybe slower application code.
Do you have some resources or material I could check to learn more?
Example code: https://github.com/sivers/store
This talk is more Oracle specific but with some minor changes you can apply the same ideas to postgres: https://www.youtube.com/watch?v=GZUgey3hwyI
Personally I am using an architecture similar to https://sive.rs/pg in my personal projects and I am very happy with it. It is important that you put data and procedures/views in different schemas so that you can use migrations for your data but automatically delete and recreate the procedures/views during deployment. Also use pgtap or something similar for testing.
Appreciate the info, thanks!
For canaries there's growing support for branching the database which can help.
But in the end, this like all things requires balance. Putting everything in there can lead to pain down the road, for example I wouldn't follow the http part.
My use case is with app's local sqlite and I have a lot of code transforming the returned rows into JSON. It works but feels slower and to divorced from the data.
Much of this discourse around SQL "not having structure" seems to be about arrogance rather than ignorance. It would take 10 seconds with ChatGPT to resolve this deficit, but for some reason we insist on writing entire blogs and burning hundreds of aggregate hours commenting about a make-believe world wherein views and CTEs don't exist.
> A relation [table] whose domains [column types] are all simple [not relations] can be represented in storage by a two-dimensional column-homogeneous array of the kind discussed above. Some more complicated data structure is necessary for a relation with one or more nonsimple domains. For this reason (and others to be cited below) the possibility of eliminating nonsimple domains appears worth investigating.⁴ There is, in fact, a very simple elimination procedure, which we shall call normalization.
But non-normalized relations support the kind of nested structure the eminent Dr. Brandon wants, without resorting to JSON or abandoning the strong uniform typing we have with SQL. Darwen & Date's The Third Manifesto https://www.dcs.warwick.ac.uk/~hugh/TTM/DTATRM.pdf includes group and ungroup operations which translate back and forth between normalized and non-normalized relations.
I've been playing around with some of these ideas using some rather horrific atrocities perpetuated against Lua operator overloading in http://canonical.org/~kragen/sw/dev3/cripes.lua. I haven't added joins or ungrouping to it yet, but I think it might be a prototype of something promising for this kind of use case.
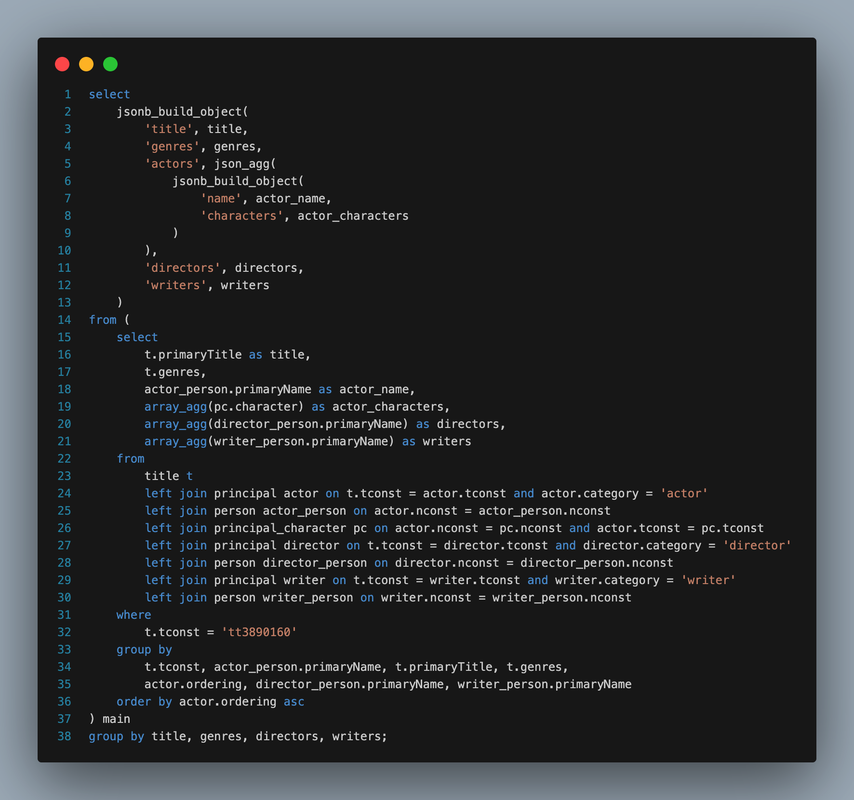
select jsonb_build_object( 'title', title, 'genres', genres, 'actors', json_agg( jsonb_build_object( 'name', actor_name, 'characters', actor_characters ) ), 'directors', directors, 'writers', writers ) from ( select t.primaryTitle as title, t.genres, actor_person.primaryName as actor_name, array_agg(pc.character) as actor_characters, array_agg(director_person.primaryName) as directors, array_agg(writer_person.primaryName) as writers from title t left join principal actor on t.tconst = actor.tconst and actor.category = 'actor' left join person actor_person on actor.nconst = actor_person.nconst left join principal_character pc on actor.nconst = pc.nconst and actor.tconst = pc.tconst left join principal director on t.tconst = director.tconst and director.category = 'director' left join person director_person on director.nconst = director_person.nconst left join principal writer on t.tconst = writer.tconst and writer.category = 'writer' left join person writer_person on writer.nconst = writer_person.nconst where t.tconst = 'tt3890160' group by t.tconst, actor_person.primaryName, t.primaryTitle, t.genres, actor.ordering, director_person.primaryName, writer_person.primaryName order by actor.ordering asc ) main group by title, genres, directors, writers;
"What if an SQL statement returned a database?"
- cte
- recursive
- with (in SQL code, not prose)
- connect (as in Oracle's CONNECT BY)
SQL deals with hierarchical data just fine. You just have to learn about how (recursive CTEs).
So one can technically create a projection/view that is tailor-made for a query that needs to display some data. Of course it is no often possible to retrieve all the data with a single select command.
So joins and multiple queries are simply inherent to complexity of data we store nowadays.
Anyway, years ago, i have moved to a db model where every entity is stored as a blob in a dedicated column and every additional column, beside id, is indexed. So there is no wasted space and a ton of columns that only hold data but are not used for filtering. I can run data-efficient queries that yield a list of ids of blobs to load or the blobs themselves and then i extract any necessary data out of those blobs(entities) on the application level. So the database us purely a blob store + few fast indices.
At this time, there are 12 services that make up the entire application. Event-sourcing is what allows infinite scaling and CQRS.
ES is the pinnacle of technology in the web sector, but it comes with a lot of overhead and time to market is significantly slowed down. So it is not something every project can or should consider implementing.
with theTitle as (
from title.parquet
where tconst = 'tt3890160'
),
principals as (
select array_agg({id:principal.nconst,name:primaryName,category:category})
from principal.parquet, person.parquet
where principal.tconst = (from theTitle select tconst)
and person.nconst = principal.nconst
),
characters as (
select array_agg(c.character) as characters, p.u.name
from principal_character.parquet c
join (select unnest((from principals)) as u) p
on c.character is not null and u.id=c.nconst and c.tconst=(select tconst from theTitle)
group by p.u
)
select {
title: (select primaryTitle from theTitle),
director: list_transform(
list_filter((from principals), lambda elem: elem.category='director'),
lambda elem: elem.name),
writer: list_transform(
list_filter((from principals), lambda elem: elem.category='writer'),
lambda elem: elem.name),
genres: (select genres from theTitle),
characters: (select array_agg({name:name,characters:characters}) from characters),
} as result
STRUCT(
title VARCHAR,
director VARCHAR[],
writer VARCHAR[],
genres VARCHAR,
characters STRUCT(
"name" VARCHAR,
characters VARCHAR[]
)[]
)Table-valued functions (I think these are not exclusive to GoogleSQL?) are also very nice. Every time I see scripts with a long block of with statements part of me dies inside.
With its JSON arrow operators and indexed expressions, SQLite makes a really nice JSON document store.
Assume you have a "cars" table with nothing but a "cars" column that is a JSON blob. Then selecting the models of all cars is just:
SELECT cars->>'model' FROM cars
SELECT JSON_UNQUOTE(JSON_EXTRACT(cars, '$.model')) FROM carsCan ‘model’ be a variable, or does it have to be a constant literal?
Another example is UUIDs. Instead of transferring 16 bytes, the libraries deal with wasteful string representation. I'm sure you can bring another examples.
Nonetheless, for majority of data JSON as DB output format is alright.
The OLAP world has much nicer type systems eg https://duckdb.org/docs/stable/sql/data_types/union.html.
Well, LEFT JOIN is the basic SQL knowledge, surprising the author doesn't know that.
> because sql wasn't designed to produce hierarchical data
Well, SQL was designed _because_ of the shortcomings of hierarchical DBMSes.
Also, author uses PostgreSQL, so could easily use ARRAY_AGG(), and Composite Types to get the exact answer they need in one query, no need for hacks. They can even make their own custom type for type safety, if needed.
Even with left joins things are even clunkier because you no longer have the clunky but straightforward n * m formula for number of rows, you have something even more confusing: n * max(1, m)
A query like
select users.*, orders.* from users left join orders on orders.user_id = users.id
type SingleReturnRow = { users: {id: ..., }[], orders: {user_id: ..., id: ..., }[]}
type Return = SingleReturnRow[]
I don't think a larger change in the query language would even be needed.
Even better of course would be a return value like
type SingleReturnRow = { user: User, orders: Order[] }
Of course in PG now you can use
select users.*, json_agg(orders.*) as orders from users left join orders on orders.user_id = users.id group by users.id
However I proposed a hierarchical result for such cases a long time to our database, but couldn't convince enough people. json_agg came later at there all the machinery is there, it would "just" require exposing this to the protocol and adapting all clients to understand that data format ...
The output format is either raw Arrow DenseUnions (e.g. via FlightSQL) or Transit via a pgwire protocol extension type.
select primaryTitle, person.primaryName
from title, principal, person
where title.tconst = 'tt3890160'
and title.tconst = principal.tconst
and principal.nconst = person.nconst
and principal.category = 'director';
select primaryTitle, person.primaryName
from title
join principal on principal.tconst = title.tconst
join person on person.nconst = principal.nconst
where title.tconst = 'tt3890160'
and principal.category = 'director';
If ambiguity of column names are low enough you could also use `join person using(nconst)`
It often becomes more interesting to find what bits are reused in several places and can get broken out into a useful cache (like person id → person name, thumbnail url, person url, …) than making a custom query for each view
That completely changes how you do queries as you can cut a bunch of joins. Instead you get a partial data set from the query that you then throw on a function or service that populates all the referenced ids from a cache, and backfills (and caches) any missing ones (preferably with a single query for a list of people in the example).
We built a GraphQL / SQL hybrid expression language that does just this here: https://docs.gadget.dev/guides/data-access/gelly#gelly , curious what yall think.
Joining tables is composing complex facts from simple ones, and is the opposite of normalization which is decomposing complex facts into simpler ones. The ability to join tables on arbitrary conditions is fundamental to the ability to ask a DBMS complex questions and have it respond with all the facts that match that question.
Like, left joins have been around since SQL-92, so the query not returning a result when there is no director is a skill issue.
Nowadays, you can run a JSON or XML query and have the DB return your results in a hierarchical format.
> - In a small team (averaging ~3 people, I think?) in a little under a year, we built a SQL query planner that passed the >6 million tests in the sqlite logic test suite.
> - I figured out how to decorrelate arbitrary SQL subqueries (I wasn't the first person to figure this out, but I got there independently).
> - I demonstrated a mode of consistency failure in various popular streaming systems that I believe was not widely understood at the time.
I think it is likely that the reason you disagree with him is not that he "don't understand tabular data" and has "a skill issue". Unless you're secretly Michael Stonebraker?
You write:
> Nowadays, you can run a JSON or XML query and have the DB return your results in a hierarchical format.
You may not have noticed this, but the post you are commenting on explains how to run a JSON query and have the DB return your results in a hierarchical format.
I didn't read beyond the article. I only responded to what was in the post.
He didn't use capabilities SQL has had for decades, made a bad query, and used that to build his argument about how bad SQL is.
The ORM tables could've been written in one query that returns a tabular format of hierarchical data, which the front end could use.
What does that look like? It looks like the kind of underlying tabular format JSON & XML queries require. He didn't do that with his non-JSON examples.
Yes, the framework would need to turn it into an object. Yes, there is data duplication in some fields. While not ideal, it's still better than the ORM example because you're not splitting it up into multiple queries.
His JSON example undercuts his main argument. The DB is fully capable of returning the representation he wants. It's also more complex than necessary with all the JSONB_AGGs in the subqueries. Then he says you can see the duct tape.
So yeah, it reads like a front end person who never really learned modern SQL. Or maybe it's someone who knows better who is making a bad faith argument. Either way, it's just a bad take.
For another, postgres has more JSON functions than just jsonb_agg.
https://www.postgresql.org/docs/current/functions-json.html
I don't have time to write something out right now, but there are definitely options.
It's kind of a red flag, though, that you didn't answer my question about how you would restate his main argument. It suggests to me that you're just here to flame instead of to have a productive discussion.
I kind of thought it was a red flag that you were accusing me of not understanding the post, which is about how SQL is bad at hierarchical data, while defending the bad SQL he used to defend his argument. But I didn't make a big deal out of it.
> I'm not sure there's a better option in Postgres, and I'm not convinced you understand his main argument. How would you restate it?
Rather than asking you to demonstrate the better way of writing the query.
I think you don't understand what the post is about, you don't understand what the query is trying to achieve, you don't know a better way to do it, and you're just engaging in ego defense instead of contributing anything.
Also, often, the transactional database servers is more difficult to scale than application servers so from a technical standpoint, it makes sense to do this glue work in app code.
This depends on the transaction isolation level. If you use snapshot or serializable this should be the case (but you may have aborted transactions due to optimistic concurrency).
https://www.postgresql.org/docs/current/transaction-iso.html
I’m likely misunderstanding what you mean by time.
+-------------------+
| |
| | +One of the worst systems I’ve ever had to deal with. Not necessarily because of the db itself, but because of the implications of its use. It serves an incredibly narrow purpose. Everywhere I’ve worked at has had a team practically dedicated to moving data from a document store to a relational db so it could be actually usefully used for analytics and across disparate systems.
When querying db for schema you don't get enough information to be able to generate very good code in all cases.
Language-first way (define schema in language and generate database schema/migrations) ties you to just one language. And usually these tools don't support using all database features.
Even then, if you really wanted to, you can absolutely make a tree-like structure in SQL in a variety of ways: adjacency lists, nested sets, closure tables, etc.
That's kinda the problem—rather there being 1 way to make a tree-like structure in SQL, that works correctly, there's a lot of ways to do it, and they all have different tradeoffs, and they're all a bit obnoxious.
If they needed only one thing, sure. However, often UX needs to look at the same data in very different ways, and an efficient representation for one need might not be at all efficient for the next (which may not even be known as a need for several years).
* Store relation-on-cell: All the trick of so called `nosql` is that they can do nested data. THAT IS ALL
* Then, `join` is already inline
* Then, instead of the very poorly named `GROUP BY` it could has REAL `GROUP BY`!
That is all is need at the core
This is a very interesting area for exploring a new kind of ORM. I find the whole "CRUD monkey" shtick preached by DHH et al quite lacking for expressing the kind of hierarchical data structures developers need.
GraphQL has the API servers (database clients) marshalling the data into heirarchies (nested data) and managing consistent results (e.g. streaming updates).
The article is arguing that the database should be more capable of understanding queries that request nested data (and separately Jamie has spoken in favour of databases that encourage end clients getting up-to-date/internally-consistent results).
My two cents is that it's a crutch having SQL rely on JSON instead of it's own first-class nested data (which would be any given value (field, aka cell) can itself be a relation - at least postgres has array values but they are challenging to index/use keys programmatically).
Don't get me wrong, JSONB is great but I see a lot of people simply slap on a JSON column to anything that requires more complexity without trying to first solve it through RDBMS relations.
A lot of teams already have their data sitting in Postgres, Mongo, or a lakehouse. Spinning up a separate graph database just for traversals often means duplicating data, building pipelines, and keeping two systems in sync. That’s fine if you need deep graph algorithms, but for many workloads it’s overkill.
What some folks are exploring now is running graph queries directly on top of their existing data, without having to ETL into a dedicated graph DB. You still get multi-hop traversal and knowledge graph use cases, but avoid the “yet another database” tax.
So yeah...graph databases are great, but they’re not the only way to model or query graphs anymore.
At least personally when Jamie says something I listen. :)
And, in practice a lot of these frontenders end up storing a JSON blob with either no nesting or just one level of nesting that looks a lot like a database schema built by someone being stubborn about not normalising data. In some sense that is fine, databases seem to be learning to just treat simple JSON blobs as normalised data but it is hard to make that as efficient as a guaranteed schema. Plus larger companies often end up having to hire a dedicated team of engineers to properly normalise data so other people can use it.
{kind=link}