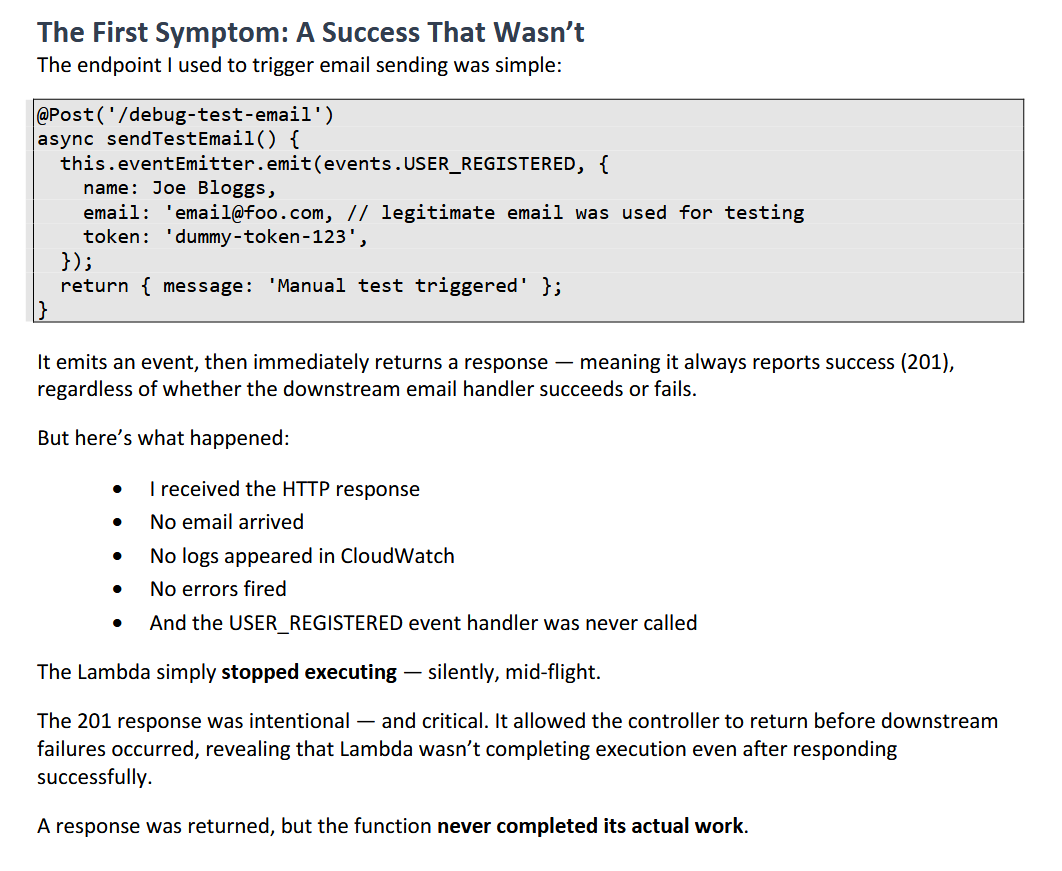
> It emits an event, then immediately returns a response — meaning it always reports success (201), regardless of whether the downstream email handler succeeds or fails.
It should be understood that after Lambda returns a response the MicroVM is suspending, interrupting your background HTTP request. There is zero guarantee that the request would succeed.
1: https://docs.aws.amazon.com/lambda/latest/dg/lambda-runtime-...
As an aside I find it strange that the author spent all this time writing this document but would not provide the actual code that demonstrates the issue. They say they wrote "minimal plain NodeJS functions" to reproduce it. What would be the reason to not show proof of concept code? Instead they only show code written by an AWS engineer, with multiple caveats that their code is different in subtle ways.
The author intends for this to be some big exposé of AWS Support dropping the ball but I think it's the opposite. They entertained him through many phone calls and many emails, and after all that work they still offered him a $4000 account credit. For comparison, it's implied that the Lambda usage they were billed for is less than $700 as that figure also includes their monthly AWS Support cost. In other words they offered him a credit for over 5x the financial cost to him for a misunderstanding that was his fault. On the other hand, he sounds like a nightmare customer. He used AWS's offer of a credit as an admission of fault ("If the platform functioned correctly, then why offer credits?") then got angry when AWS reasonably took back the offer.
That’s the whole point and it’s not the behavior your comments describe.
This is not the right way to accomplish this. If you want a Lambda function to trigger background processing, you invoke another lambda function before returning. Using Node.js events for background processing doesn't work, since the Lambda runtime shuts down the event loop as quickly as possible.
If you talk about documentation, and in this thread there have been many mentions of it, without citing specific paragraphs, we could start with this one from here [1]:
"Using async/await (recommended)"
"...The async keyword marks a function as asynchronous, and the await keyword pauses the execution of the function until a Promise is resolved..."
Or
"Using callbacks"
"...The function continues to execute until the event loop is empty or the function times out. The response isn't sent to the invoker until all event loop tasks are finished. If the function times out, an error is returned instead. You can configure the runtime to send the response immediately by setting context.callbackWaitsForEmptyEventLoop to false..."
[1] https://docs.aws.amazon.com/lambda/latest/dg/nodejs-handler....
It actually seems, the most likely that happendd here, were random disconnects from the VPC, that neither the author or AWS support were able to contextualize.
This response seemed illuminating:
https://www.reddit.com/r/aws/comments/1lxfblk/comment/n2qww9...
> Looking at (this section)[https://will-o.co/gf4St6hrhY.png], it seems like you're trying to queue up an asyncronous task and then return a response. But when a Lambda handler returns a response, that's the end of execution. You can't return an HTTP response and then do more work after that in the same execution; it's just not a capability of the platform. This is documented behavior: "Your function runs until the handler returns a response, exits, or times out". After you return the object with the message, execution will immediately stop even if other tasks had been queued up.
OP seems to be fixated on wanting MicroVM logs from AWS to help them correlate their "crash", but there likely no logs support can share with them. The microVM is suspended in a way you can't really replicate or test locally. "Just don't assume you can do background processing". Also to be clear, AWS used to allow the microVM to run for a bit after the response is completed to make sure anything small like that has been done.
It's an nondeterministic part of the platform. You usually don't run into it until some library start misbehaving for one reason or another. To be clear, it does break applications and it's a common support topic. The main support response is to "move to EC2 or fargate" if it doesn't work for you. Trying to debug and diagnose the lambda code with the customer is out of support scope.
Same technical cause, it uses background tasks to upload logs. If the Function exits, the logs aren't sent.
This has been fixed since, but for a while generated a lot of repeated support tickets and blog articles.
This is one of the main technical differences between Azure Functions and Google Cloud Run vs Lambda. Azure and GCP offer serverless as a billing model rather than an execution model precisely to avoid this issue. (Among many other benefits*)
Both in Azure and GCP you listen and handle SIGTERM (on Linux at least, Azure has a Windows offering and you use a different Windows thing there that I’m forgetting) and you can control and handle shutdown. There is no “suspend”. “Suspending nodejs” is not a thing. This is a super AWS Lambda specific behavior that is not replicable outside AWS (not easily at least)
The main thing I do is review cloud issues mid size companies run into. Most of them were startups that transitioned into a mid size company and now need to get off the “Spend Spend Spend” mindset and rain in cloud costs and services. The first thing we almost always have to untangle is their Lambdas/SF and it’s always the worst thing to ever untangle or split apart because you will forever find your code behavior differently outside of AWS. Maybe if you have the most excellent engineers working with the most excellent processes and most excellent code. But in reality all Lambda code takes complete dependency on the fact that lambda will kill your process after a timeout. Lambda will run only 1 request through your process at any given time. Lambda will “suspend” and “resume” your process. 99% of lambdas I helped move out of AWS have had a year+ trail of bugs where those services couldn’t run for any length of time before corrupting their state. They rely on the process restarting every few request to clear up a ton of security-impacting cross contamination.
* I might be biased, but I much much prefer GCR or AZF to Lambda in terms of running a service. Lambda shines if you resell it. Reselling GCR or AZF as a feature in your application is not straight forward. Reselling a lambda in your application is very very easy
What does "no more code to execute" mean to you? How would you define that?
This person should not be trusted to accurately recount a story, I would be sceptical of any claim in the doc.
It use to be the case if you were interviewing for an SDE position, you were specifically told not to mention specific AWS services in the system design rounds and speak of generic technologies.
At the same time, I've had two separate Apple SREs in the last 5 years tell me that I should never trust their cloud services.
If you can't see it and can't control it yourself, then you accept these things silently.
My distrust for this goes as far as the only thing actually being subcontracted out for me is Fastmail, DNS and domains and the mail is backed up hourly.
The document is long, and the examples seem contrived, so anyone is free to correct me but as I understand it the lambda didn't crash, after you returned 201, your lambda instance was put to sleep. You aren't guaranteed that any code will remain running after your lambda "ends". I am not sure why AWS Support was unable to communicate this OP.
If you are using Lambda with a function URL, you aren't guaranteed that anything after you return your http response remains running. I believe Lambda has some callbacks/signals you can listen to, to ensure your function properly cleans up before the Lambda is frozen, but if you want the lambda to return as fast as possible it seems you are better off having your service publish to an SQS queue instead.
Edit: I see he's the CTO of an AI company.
- Constant bulleted lists with snappy, non-punctuated items.
- Single word sentences to emphasize a point ("It was disciplined. Technical. Forensic.")
- The phrasing. e.g. the part about submitting to Reddit: "This response was disproportionate to the activity involved: a first-time technical post, written with precision, submitted to the relevant forum, and not yet visible to any other user." Who on earth says "written with precision" about their own writing?
To be clear, I don't think it's a fabricated account. I also don't think it was a one-shot. OP probably iterated on it with GPT for quite some time.
For whatever reason, it constantly uses rhetorical reclassification like “That’s not just X. That’s Y.” when it's trying to make a point.
In GPT's own words:
``` ### Why GPT uses it so often:
- It sounds insightful and persuasive with minimal complexity. - It gives an impression of depth by moving from the obvious to the interpretive. - It matches common patterns in blog posts, opinion writing, and analyst reports. ```
I think that last point is probably the most important.
https://lyons-den.com/CV/David_Lyon_CTO_CV_2025.pdf
EDIT: he has added three(!) separate mentions of the same incident to his résumé
what a weird thing to brag about on your resume. And then he says "case study cited on ... HackerNews" - that's funny!
No David Lyon in there. It goes straight from Luncheon to Martinez and Lynch to Mackey for Graduates and Candidates, respectively. Page 35
Interesting if the whole character was a scam. The current employer is not disclosed in his CV, qualifications are fake (also flagged on Reddit by someone who says they are an ex colleague https://www.reddit.com/r/aws/comments/1m0198c/comment/n3fiwk...) - what else?
To me personally, calling yourself a CTO with a CV entry that amounts to what an L5 in a FAANG does in a half, is a bit ridiculous. What title would HN recommend for such a position, instead?
Maybe we should be asking why the OP was not able to hear what AWS was telling them. I think there is a fairly troublesome cognitive bias that gets flipped on when people are telling you that you're wrong — especially when all your personal branding and identity seems to be about you being right.
I sympathize with OP because debugging this was painful, but I'm sorry to say this is sort of just a "you're holding it wrong" situation.
AWS Support is generally ineffective unless you're stuck on something very simple at a higher level of the platform (e.g. misunderstanding an SDK API).
Even with their higher tier support - where you can summon a subject matter expert via Chime almost instantly - they're often clueless, and will confidently pass you misleading or incorrect information just to get you off the line. I've successfully used them as a very expensive rubber ducky, but that's about it.
"Failure" != "Bug"
Sounds like he needs a holiday at the least.
The mere idea that reddit has a special Amazon protection team that is the cause of his account suspension is ludicrous.
Hopefully this exposure will help him out.
looks lile he took down his site after some other commentators in this discussion noticed some discrepencies in his resume. specifically his claims of having a PhD and a JD. Con men never learn, they just play the next fool.
While the author is probably correct in this being a platform level bug (I have not ran the code to confirm myself though), they should stop being so angry at a corporation doing what corporations do which is run a big bureaucracy and require extraordinary amounts of extra communication. One of job requirements of a principle engineer, often making hundreds of thousands if not millions of dollars a year, is to communicate across levels because it is so hard to do this effectively without being angry or losing your cool.
`As a solo engineer, I outpaced AWS’s own diagnostics, rebuilt our deployment stack from scratch, eliminated every confounding factor, and forced AWS to inadvertently reproduce a failure they still refused to acknowledge.`,
I do not think that a solo engineer would have the economic clout to get AWS to pay attention to the bug you found. Finding a bug in a system does not imply any ability to fix a bug in a bureaucracy.
Plus, given the tone of the article, I have a funny feeling that the author may have rubbed people in AWS the wrong way, preventing more progress from being made on their bug.
But, a wise fellow once said, "all progress in this world depends upon the unreasonable man".
They seem to want a fast response with background processing of a potentially slow task. The answer on Lambda (and honestly, elsewhere) is having this function send the payload to a queue, and processing the queue with another function.
The fact that support didn’t engage us seems odd as we have gotten engaged for far more silly stuff.
However, in this case you should have awaited for the response from event emitter.
The lambda execution model clearly does not allow you to run things past the response as execution is frozen by the sandbox / virtualization software. From there, you’ve most likely caused a timeout when issuing the request.
I guess it's possible someone did explain it to him, and David hasn't mentioned that in his diatribe.
There was a few days of back and forth which should have been resolved by saying "please read the how lambda works" section of the documentation.
That job was a glorified call center; I didn't last very long.
Not just possible. Quite likely. It seems very clear the answer was "yes, that's how it works on Lambda, and it is not going to change" and this person said "but I want it to work the other way on Lambda".
If the designer expects a reliable system that guarantees processing of the request after the return of the status, they cannot rely on a server to not crash the moment the response was sent to the wire. Serverless enforces this well, yet people try to force their view of infinitely reliable infrastructure, which is not based in reality.
However if it is worth anything I did work at AWS for 3.5 years (AWS ProServe). I knew almost immediately what the issue was as soon as I read the article and knew it was documented and expected behavior.
Given the AWS Active mention, the author may be living off free AWS credits and has a modest spend afterwards.
Not sure if a seven-week investigation is the best use of engineering resources at early startups. Once you hit the limits of PaaS platforms, going EC2/Fargate/Kubernetes seems like a more pragmatic option. AWS Lambda is not for async jobs; once you return HTTP, it's done. Not convinced this is a bug.
However, he did manage to get to the front page of Hacker News, and the write-up is quite decent (minus the AWS blame part).
I would suggest taking this down and hope it silently goes away. If you're a fractional CTO for a startup that spent a week on this, then spent god knows how long to rearchitect for Azure based on this... The startup might find this actionable.
---
EDIT:
After looking into this more, it seems the `context` passed to the Lambda entrypoint has a `callbackWaitsForEmptyEventLoop` parameter, which defaults to True. https://docs.aws.amazon.com/lambda/latest/dg/nodejs-context.....
Did you set this to False somewhere?
But one thing bothers me…wouldn’t the author have encountered the exact same behavior in Azure? I guess I really will have to read this paper to find out.
It was typical Azure strategy of rushing out a product to show they have all the same features as AWS. It may have improved since I last touched it in 2018.
Well... they can![1]
It's definitely a thing in traditional always-running web server processes, which is all people know these days.
Many developers have never written a code for a short-lived process outside of maybe school exercises. Things like CLI tools, background jobs, etc...
[1] I get "Later!" printed out... most of the time: https://dotnetfiddle.net/ng93d4
However, it is still funny when you think that in regular servers you still finish when you respond to the request.
My dog keeps getting angry at the door. It won’t open automatically.
This also shows the best and worst of AWS: things are documented, but not always when/where/how you need them. You will still need to learn a few things the hard way when getting your toes wet (so use those "innovation tokens" sparingly).
> Exposed and published a confirmed AWS Lambda runtime failure (Node.js in VPC) — silently crashing workloads post-request. Outdiagnosed L5 AWS engineers using Docker-based rebuilds, AL2023 parity, and deep forensic isolation. Case study cited on Dev.to, Hashnode, and HackerNews.
He must also be completely oblivious to external feedback, given his "Case study cited on HackerNews" is all about his methodology and attitude being torn into pieces.
Bro needs a dose of mechanical sympathy and intellectual vulnerability.
https://will-o.co/gf4St6hrhY.png (not my screenshot)
I get that some big businesses are using JavaScript on the backend, but I’ll bet almost every single one would be better off switching to a type-safe, compiled language.
{kind=link}