> Code Data For coding problems, we curate a high-quality training set comprising open-source datasets and our newly collected problem set. We remove problems without test cases. For problems with golden solutions, we exclude those where the golden solution failed to pass all test cases. For problems without golden solution, we discard problems where no test case can be solved in 16 rollouts of advanced reasoning models. Similar to math data, we utilize an SFT version of MiMo-7B to filter out easy problems that are perfectly solved in all 16 rollouts. This rigorous cleaning process yields 30K code problems.
> During each RL iteration, we evaluate thousands of problems to compute the rewards, with each problem potentially containing hundreds of test cases. To improve reward computing efficiency and eliminate GPU idle time, we developed an online judge environment that enables parallel execution of extremely high-volume unit tests.
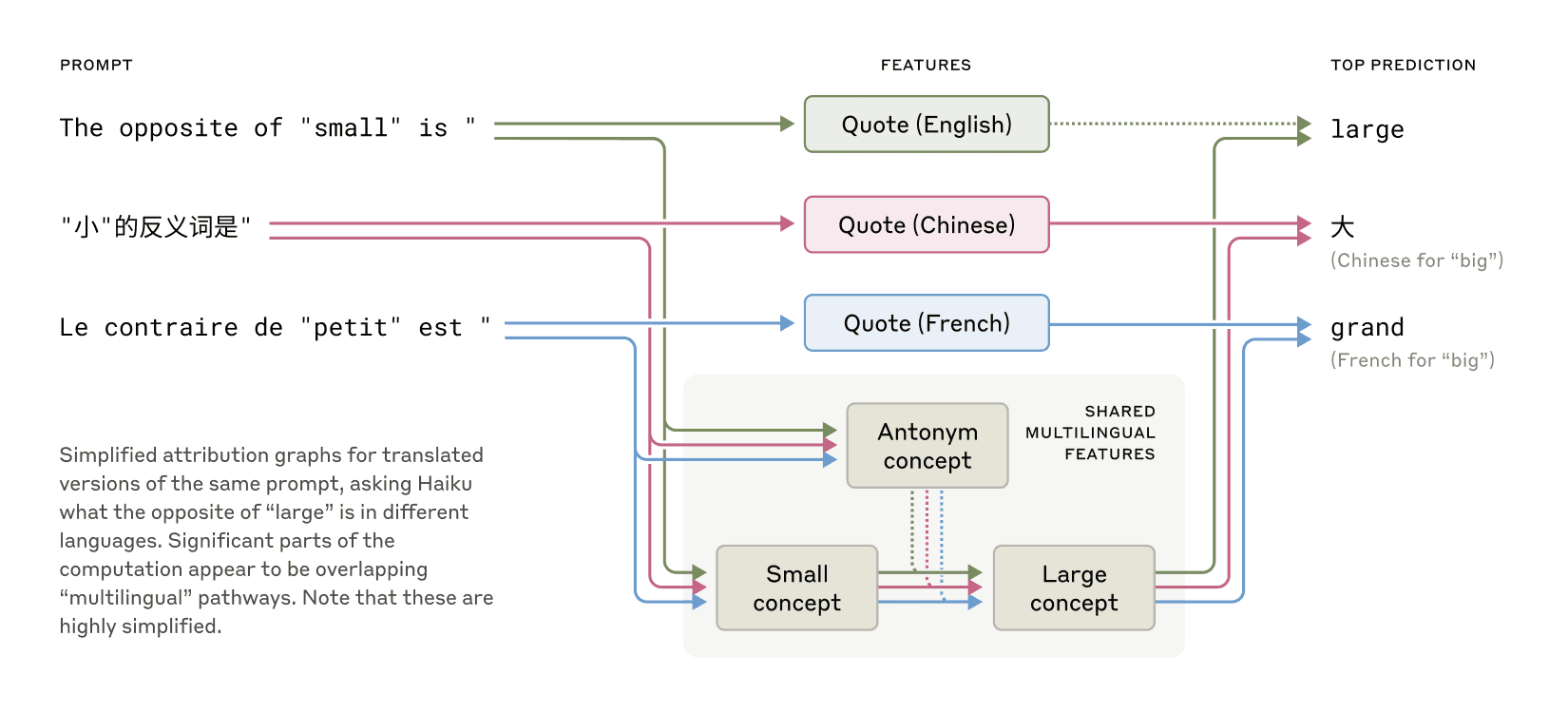
It's clearly impossible for me to try anything in Chinese, I'd need a translation.
So the example they give:
English: The opposite of "small" is " → big
French: Le contraire de "petit" est " → grand
Chinese: "小"的反义词是" → 大
Cool graphic for the above [2]
So while English is the lingua franca of the interenet and represents the largest corpus of data, the primary models being built are able to use an English dataset to build associations across languages. This might create significantly stronger AI and reasoning even for languages and regions that lack the data, tech and resources to build local models
[1] https://www.anthropic.com/research/tracing-thoughts-language...
[2] https://www.anthropic.com/_next/image?url=https%3A%2F%2Fwww-...
Only place where russian is in top 5 is in Wikipedia views. Russian part of internet steadily goes down, as russian imperialism crumbles.
https://commoncrawl.github.io/cc-crawl-statistics/plots/lang...
I wonder where this discrepancy comes from
would be interesting if yandex opened some data sets!
https://arxiv.org/pdf/2405.04434#page=12
> Our tokenized pretraining corpus contains 8.1T tokens, where Chinese tokens are approximately 12% more than English ones.
Is the lack of existing corpus just an extra hurdle for Hanzi-first models that are also leading the pack in benchmarks?
Many LLMs are trained on synthetic data produced by other LLMs. (Indirectly, they may be trained on pirated books. Sure. But not directly.)
But yes, 'first generation' models would be trained on human text almost by definition. My comment was only to contradict the claim that 'all LLMs' are trained from stolen text, by noting that some LLMs aren't trained (directly) on human text at all.
This is a large part of it. Kai-Fu Lee's company (https://www.01.ai/) has been publishing open source Chinese language/market focused models pretty early, but the entire conversation around Chinese tech just isn't available to you if you don't speak Chinese, in particular these days given that good English language reporting on the Chinese tech sector just seems very scarce.
The literature that survived thousands of years are cream of the crop; you won't find lots of random unimportant dialog between people thousands of years ago, but you find that on Reddit.
It must be very bad when you see the walking turd that Google search has become over the years…
Could it be that being multilingual results in a larger pool of human knowledge on the technical side compared to training on just a single language or 2. And on the business side, supporting more languages results in a larger TAM (total addressable market). Using english-language dataset for training LLMs is the default, not the other way like you insinuate.
What would a hypothetical "Mandarin-first" model look like to you?
I challenge the notion that the current models are "English-first" - that is an unsubstantiated opinion not supported by fact. I bet, dollars to donuts, these models are SoTA in Mandarin as well. When framed that way, asking "Why are they marketed as English-speaking models outside of China" or "Why are they really good at English" are simply not interesting questions - they have obvious answers.
Given a language-agnostic prompt like "12 + 89", any explanatory text it outputs could be expected to be in Mandarin most of the time.
According to this test, Xiaomi's MiMo-7B-RL is an English-first model.
Now I'm curious how Mistral models would respond to a "language-agnostic" phrases like "Rendezvous" or "coup d'etat"
In contrast, your examples would be spelled « rendez-vous » and « coup d’État » in French, i.e. easily distinguishable from their English descendants.
No need for scare-quotes, Latin script is a proper noun and a technical term with precise meaning wrt text encoding - not "what I think."
> the exact same symbols are also used by Mandarin speakers, as well as in numerous other scripts. Writing math in Chinese
Which unicode code points do the Mandarin speakers and "numerous other scripts" use to write "12 + 89"? Could it be the very same code points as Latin script, which then are tokenized to the same vectors that the LLMs learn to associate more with English text rather than CJK in the latent space?
> i.e. easily distinguishable from their English descendants.
You're making broad assumptions about the tokenization design here that do not apply universally.
This smacks of "I saw a headline once"-itis. Especially the fact that you refer to the Chinese characters as "calligraphy characters", as if that were the general term or something.
https://www.globaltimes.cn/content/747853.shtml
https://www.bbc.com/news/blogs-china-blog-28599392
Or more recently this one about character amnesia
https://globalchinapulse.net/character-amnesia-in-china/
None of these really mean that English has won, though. Rather that phonetics-based writing systems are easier to remember and use, especially in conjunction with digital systems that make it easy to map sound and context to symbols.
I wouldn't be surprised if characters are faster to read though. In English we have all these subconscious shortcuts like looking at the shape of the word, first and last letters, etc. But I think symbology can convey more at a glance. Thus the popularity of emoji
I'm pretty sure there was some controvery in the linguistic blogging community even at some stage over the last couple of years, with someone writing an essay claiming the Chinese character system was in some sense less advanced and maybe on the way out, and this leading to a serious response or two, the usual fiery academic affair. I can't locate it this instant though.
I moreso meant for OP's low-effort dramatisation to not go unanswered. Framing it as "winning" some sort of language battle is particularly silly.
Your musings are interesting though, and the topic certainly is a fascinating one. Languages that use morphemes for writing are wild. Symbology is a cool word also - surely there has to be a lisp blog somewhere with that word in the title.
Uh? Pinyin input is by far the most popular input technique in China. I rarely see anyone using handwriting input.
That being said, it has nothing to do with English winning. It's just a Chinese input technique that uses the latin alphabet. English fluency in China is not very common, especially spoken English.
And very true about the English. With some exceptions (of course), folks here maybe know a handful of words at best, and even then, pronunciation is usually pretty rough. People here really aren't using it; they are perfectly comfortable with their Chinese, and why wouldn't they be?
Anyone saying otherwise clearly hasn't been here to see it firsthand.
By the looks of it, Pinyin (a phonetic one) won by a landslide, which I suspect this is the result of a long effort by the Chinese government to install Mandarin as the official language of China, above regional dialects (different regions would write similar characters but pronounce them differently, and defaulting to Pinyin has this "nice" effect of having people "think of how it would be pronounced in Mandarin first", even when the result are characters that would be read by a Cantonese speaker).
It could not have been further from a bilingual society.
I've not yet been to Shanghai, and while I would expect the English-speaking percentage to be a bit higher, it would still likely only be in the single-digits by my estimation.
Sad reality is that not many outside of China have the facility with Mandarin to use those models. Even non-native Mandarin speakers who claim to be "fluent", are often messing up intended meaning in text. Or making literal translations that wind up making no sense.
Inside of China, llm use will be Mandarin based. Outside, it seems to me English is the natural choice.
Irony of Irony, probably the best way for a non Mandarin speaking layman to test a Mandarin based model would be to use another LLM to translate prompts to Mandarin.
It's a sad future we're looking at.
Or a brilliant one.
Time will tell.
Happens with English as well, but non-native speakers of English still benefit from these models.
I've become pretty skeptical about eval results given what we've heard about llama4 so we'll see where this lands on the closed evals but very impressive to see.
https://github.com/ollama/ollama/blob/main/docs%2Fmodelfile....
>Single-file deployment
>Full information: all information needed to load a model is contained in the model file, and no additional information needs to be provided by the user.
https://github.com/ggml-org/ggml/blob/master/docs/gguf.md
We literally just got rid of that multi file chaos only for ollama to add it back :/
https://github.com/ggml-org/llama.cpp/blob/master/examples/m...
If you only ever have one set of configuration parameters per model (same temp, top_p, system prompt...), then I guess you can put them in a gguf file (as the format is extensible).
But what if you want two different sets? You still need to keep them somewhere. That could be a shell script for llama.cpp, or a ModelFile for ollama.
(Assuming you don't want to create a new (massive) gguf file for each permutation of parameters.)
Here is my workflow when using Open WebUI:
1. ollama show qwen3:30b-a3b-q8_0 --modelfile
2. Paste the contents of the modelfile into -> admin -> models -> OpenwebUI and rename qwen3:30b-a3b-q8_0-monkversion-1
3. Change parameters like num_gpu 90 to change layers... etc.
4. Keep | Delete old file
Pay attention to the modelfile, it will show you something like this: # To build a new Modelfile based on this, replace FROM with: # FROM qwen3:30b-a3b-q8_0 and you need to make sure the paths are correct. I store my models on a large nvme drive that isn't default ollama as an example of why that matters.
EDIT TO ADD: The 'modelfile' workflow is a pain in the booty. It's a dogwater pattern and I hate it. Some of these models are 30 to 60GB and copying the entire thing to change one parameter is just dumb.
However, ollama does a lot of things right and it makes it easy to get up and running. VLLM, SGLang, Mistral.rs and even llama.cpp require a lot more work to setup.
I meant when you download a gguf file from huggingface, instead of using a model from ollama's library.
ollama pull hf.co/jedisct1/MiMo-7B-RL-GGUF:Q4_K_M
ollama show --modelfile hf.co/jedisct1/MiMo-7B-RL-GGUF:Q4_K_MThis will show a separate entry in `ollama list` but only copy the Modelfile not the GGUF.
Alternatively, if you use the API, you can override parameters "temporarily". Some UIs let you do this easily, at least for common parameters.
Notice most of the models they are comparing with are 7B models. The exception is also an open weights model (Qwen-2.5-32B-RL-Zero). Even with 32B parameters the MiMo-7B outperforms it.
Putting a model out in public without clearly explaining how it works doesn’t meet my bar for a proper scientific exchange of knowledge. Perhaps they are being intentionally vague for competitive reasons.
RL is a generic term that can be mixed and matched with various other methods. In the context of LLMs, often some variation of RLHF is used.
But the authors don’t even say “RLHF”, much less explain their methodology. Understanding this isn’t just a matter of academic interest; it has implications for understanding and using this work.
I’m often concerned by the writing quality of ML/AI papers but this strikes me as particularly disappointing.
It is increasingly important to have confidence that the creators of AI systems are thoughtful and thorough. I want to see their reasoning. I want to understand the trade-offs they make and why.
I loaded up a random 12B model on ollama the other day and couldn't believe how good it competent it seemed and how fast it was given the machine I was on. A year or so ago, that would have not been the case.
We just need Google or Apple to provide their own equivalent of both: Ollama and OpenRouter so user either use inference for free with local models or BringYourOwnKey and pay themself for tokens/electricity bill. We then just charge smaller fee for renting or buying our cars.
I've had friends/family ask to use some of them; I declined. I don't want to do support / feature requests.
I do my planning with a combination of Grok3, and higher power OpenAI models. Once I have plan of what I want to build, I create an implemenation_plan.md with all the steps to build my solution. (Generated by the higher power models) I carefully review this plan and if it looks good, I throw it into agent mode and get to work.
my employer talks about spending 10s of millions on AI
but, even at this early stage, my experiments indicate that the smaller, locally-run models are just fine for a lot of tech and business tasks
this approach has definite privacy advantages and likely has cost advantages, vs pay-per-use LLM over API.
I think ML is more akin to open source hardware, in the sense that even when there are people with the relevent skills willing to donate their time for free, the cost of actually realizing their ideas is still so high that it's rarely feasible to keep up with commercial projects.
Problem was that of a top ten book recommendations only the first 3 existed and the rest was a casually blended hallucination delivered in perfect English without skipping a beat.
"You like magic? Try reading the Harlew Porthouse series by JRR Marrow, following the orphan magicians adventures in Hogwesteros"
And the further towards the context limit it goes the deeper this descent into creative derivative madness it goes.
It's entertaining but limited in usefulness.
[0]: https://huggingface.co/mlabonne/gemma-3-12b-it-abliterated
https://gist.github.com/estsauver/a70c929398479f3166f3d69bce...
Go look at the benchmark numbers of qwen3-4B if you think these are unrealistic.
> LLM benchmarks are mostly bullshit right now. Wait a few years until the hype cycle returns to sanity.
This could mean a lot of things. Can you be a bit more specific? It's one thing to say benchmarks are gamed. Another to say models end up being trained on the benchmark indirectly. Another to say they the particular experimental setup during the benchmark is unclear. Another to say mapping a benchmark to a real use case is hard. Are you saying some/all of these claims?
Have you plotted MiMo versus others? Another comment suggests smaller models are performing better than expected. Any comment on that?
Personally I use Qwen 2.5, works well enough for me. Qwen 3 is a dud.
A couple things stand out to me — first is that the 7B model is trained on 25T tokens(!). This is Meta-scale training; Llama 4 Maverick was trained on 22T or so. (Scout, the smaller model: 40T).
Second, this is an interesting path to take - not a distilled model or an RL layer to get reasoning out of another model, but a from-scratch RL model with reasoning baked in; the claims seem to indicate you get a lot of extra efficiency per-parameter doing this.
I don’t have experience with Xiaomi models, so I’m cautious about this one until I play with it, but it looks like a super viable local reasoning model from the stats.
That moe strikes me as the better overall tradeoff
They could've called it Xiaomimo.
Also related reference https://en.wikipedia.org/wiki/Xiaomi#Name_etymology
I think you meant Anthropic. OpenAI is "planning" to release an open weight model this year likely competing against the Llama models. [0]
I have not seen an open weight AI model ever being released by Anthropic at all.
Source (Chinese): https://finance.sina.cn/tech/2020-11-26/detail-iiznctke33979...
I was reading a Jack Tramiel biography recently, and read that early on the two Steve's sought to sell Apple to Commodore for under a million dollars.
But with many single characters in Chinese, a Chinese person will tell you, if you ask for what a single character means, something like, "Well it's not so easy to pin down the meaning of that one. Sometimes we use it like this, and sometimes like that."
Sure, some characters have an easy meaning (for me, I think the rice in Mi is one of them!) but there's plenty where you cannot get a Chinese person to easily tell you what a single character means. I guess it's a little like, but not the same as, asking an English person to tell you, what any given "morpheme" (word part, like fac-) means. Hahaha. Not a perfect analogy tho! :)
Here's this list of morphemes I found just now thinking about this: https://www.fldoe.org/core/fileparse.php/16294/urlt/morpheme...
Seems incomplete list when you consider etymology of English words are often composed of parts from ages past! :)
And all the products would be "MRE-Phone", "MRE-Pod", hehehe :)
https://www.scmp.com/abacus/tech/article/3028654/documentary...
Here is the meaning of the name
Described here: https://finance.sina.cn/tech/2020-11-26/detail-iiznctke33979...
在后来的讨论中,我突然想到了我最喜欢的一句话——“佛观一粒米,大如须弥山”。
Translated into English, it means:
“In the later discussions, I suddenly thought of one of my favorite sayings — ‘A Buddha sees a single grain of rice as vast as Mount Sumeru.’”
This expression emphasizes the idea that even something seemingly small (like a grain of rice) can hold immense significance or value when viewed from a different perspective.
Thanks to chatgpt for translating this
{kind=link}